
Notes from the 2025 ‘AI Agents in Production’ Conference
Notes from the 2025 “AI Agents in Production” Conference
I attended this year’s “AI Agents in Production” conference, hosted by the “MLOps Community” group and wrote down some of my notes.
Talk 1: “Using Agents in Production: Past Present and Future”
Talk 1 Abstract
Prosus has shipped over 7949 agents. 15% have worked. The rest have been learning experiences. Let’s talk about what we have learned, and where we see things going.
Talk 1 Notes
- Engineers don’t build agents. People build agents. Adoption is best if it comes from bottoms-up.
- To get widescale adoption of AI agents, you need to upskill at scale and figure out how to empower people to create agents to do so.
- Give people the tools and guardrails to experiment and iterate at scale.
- A lot of the hard work comes in encoding domain knowledge.
Talk 2: “Real-Time Voice Agents in Production: Lessons from Building Human-Like Conversations”
Talk 2 Abstract
At Elyos AI, we’re not building AI to pretend to be human - we’re building AI that can perform like one: completing real tasks, with real quality and real transparency. Our agents will tell you they’re AI. We’re not replacing humans - we’re building trust that AI can help humans work better.
In this talk, I’ll share what it actually takes to make that vision real in production. From designing low-latency pipelines, to managing dialogue context and emotional tone across long calls, we’ve learned that delivering natural, useful conversations is as much an infrastructure problem as it is a language one.
We’ll cover:
How Elyos built a resilient real-time stack combining STT, LLM orchestration, and neural TTS.
Engineering patterns for error recovery, context engineering, context retention and conversational coherence.
The metrics (and human feedback) that actually predict trust and task completion.
If you’re building or deploying AI agents that interact with people, this is a behind-the-scenes look at what breaks, what works, and how we’re bringing transparent, high-performance voice AI to the real world.
Talk 2 Notes
- Voice is more complicated than speech-to-text -> LLM.
- Real-world interactions come with noise.
- Conversations are more complicated than simple tasks.
- Long conversations can stress LLMs.
- Latency is key for this use case:
- Have warm starts: workers need to be ready to go.
- Try different TTS providers.
- Invest early in observability.
- Keep tools close to the orchestration layer, to avoid network latency.
- Make workflows deterministic
- Avoid unnecessary RAG. In this use case, (1) models think pretty well already, and (2) people expect voice agents to be lower latency.
- Benchmark against human agents
- Define expected outcomes very well.
- For long conversations, summarize well and often. Leave tool calls outside of the context and push for lots of context compression.
- Transcription of email and post code and things like that is still meh for speech-to-text. More broadly, don’t annoy users when input is unclear, have a path for dealing with uncertainty.
- Always have an escalation path to a human.
- Metrics:
- time to first token (TTFT)
- groundedness
- interruptions
- repetitions
- outcome success
- sentiment
- most common failures
Talk 3: “Simulate to Scale: How realistic simulations power reliable agents in production”
Talk 3 Abstract
In this session, we’ll explore how developing and deploying AI-driven agents demands a fundamentally new testing paradigm—and how scalable simulations deliver the reliability, safety and human-feel that production-grade agents require.
You’ll learn how simulations allow you to:
Mirror messy real-world user behavior (multiple languages, emotional states, background noise) rather than scripting narrow “happy-path” dialogues. Model full conversation stacks including voice: turn-taking, background noise, accents, and latency – not just text messages. Embed automated simulation suites into your CI/CD pipeline so that every change to your agent is validated before going live. Assess multiple dimensions of agent performance—goal completion, brand-compliance, empathy, edge-case handling—and continuously guard against regressions. Scale from “works in demo” to “works for every customer scenario” and maintain quality as your agent grows in tasks, languages or domains. Whether you’re building chat, voice, or multi-modal agents, you’ll walk away with actionable strategies for incorporating simulations into your workflow—improving reliability, reducing surprises in production, and enabling your agent to behave as thoughtfully and consistently as a human teammate.
Talk 3 Notes
- Evaluating success isn’t about “did it return the right value” but rather “did it help the user reach the goal?”
- The “Agent development lifecycle”:
- Build: define goals and guardrails for the agent.
- Simulate: run simulations and regression tests.
- Release
- Evaluate: evaluate real-world conversations.
- Optimize: improve agent performance.
I like the following interface for a simulation platform. This is great for creating simulated golden paths and example simulated user journeys.

Talk 4: Agents as Search Engineers
Talk 4 Abstract
Search is still the front door of most digital products—and it’s brittle. Keyword heuristics and static ranking pipelines struggle with messy, ambiguous queries. Traditionally, fixing this meant years of hand-engineering and expensive labeling. Large language models change that equation: they let us deploy agents that act like search engineers—rewriting queries, disambiguating intent, and even judging relevance on the fly.
In this talk, I’ll show how to put these agents to work in real production systems. We’ll look at simple but powerful patterns—query rewriting, hybrid retrieval, agent-based reranking—and what actually happens when you deploy them at scale. You’ll hear about the wins, the pitfalls, and the open questions.
The goal: to leave you with a practical playbook for how agents can make search smarter, faster, and more adaptive—without turning your system into a black box.
Talk 4 Notes
- Simplify simplify simplify! Simple backends are better for reasoning.

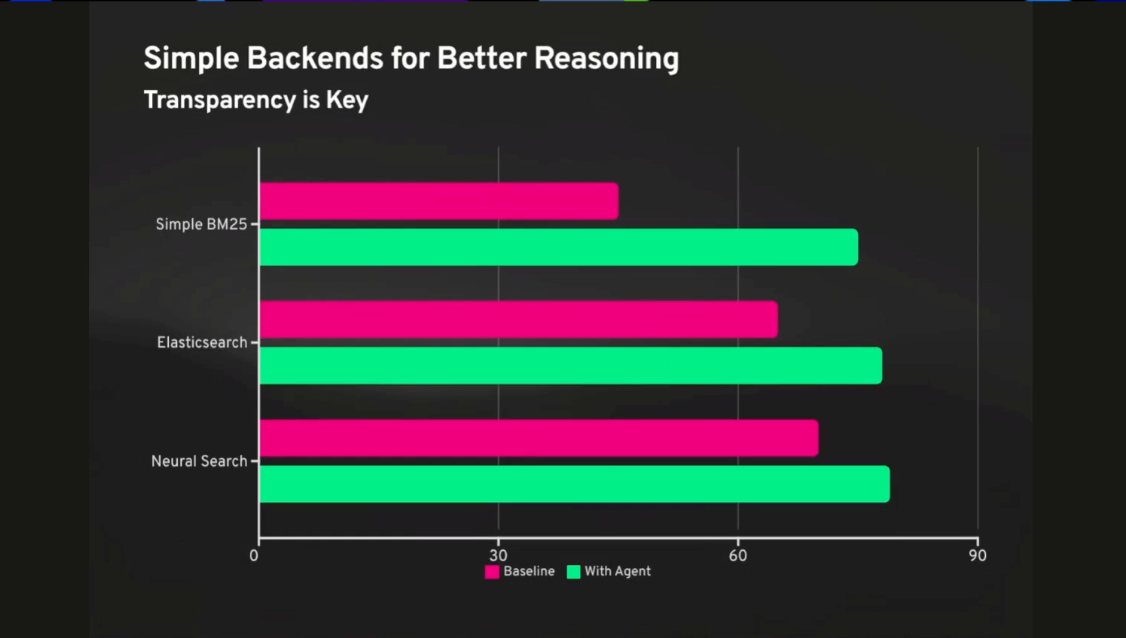
- Query-time content classification does a great job at improving query performance.

- Scoring retrieval should go beyond LLM-as-a-judge. You can look at other metrics like CTR, latency, users retrying, etc., all as other ways of measuring how good your semantic search retrieval is.
Talk 5: Architecting Trust: Multi-Agent Systems for the Misinformation Lifecycle
Talk 5 Abstract
The rapid spread of digital misinformation requires solutions that address the entire lifecycle, moving beyond single-LLM limitations. This talk, based on the author’s ICWSM research paper, offers a practitioner’s guide to a novel, five-agent system—Classifier, Indexer, Extractor, Corrector, and Verification—designed for maximum scalability, modularity, and explainability. This paper aims at automating the working of fact-checkers, which is traditionally done through a team of experts, saving millions and increasing efficiency with a human-in-the-loop system. We will get the details for each specialized agent, detailing crucial elements like model sizing and fine-tuning—for example, matching small, fine-tuned encoder models for the Classifier’s high-confidence multi-class labeling against the need for a strong reasoning LLM in the Corrector Agent. Topics include building an efficient Indexer Agent and reranking with retrieval through hybrid keyword and vector embeddings, enabling the Corrector Agent to use external search APIs for cross-validation, and the function of the Verification Agent as the final quality check for high precision.. The talk concludes by covering agent coordination protocols, cost, holistic evaluation, offline evaluation and online A/B testing and post-deployment metrics.
Talk 5 Notes
- How can we automate fact-checking with a series of agents? Sounds like it’s very dependent on one’s definition and criteria for misinformation, but presumably if you can define misinformation using a rubric that you can give to annotators, you can also develop multi-agent systems to do the same thing.
- Related paper link here.


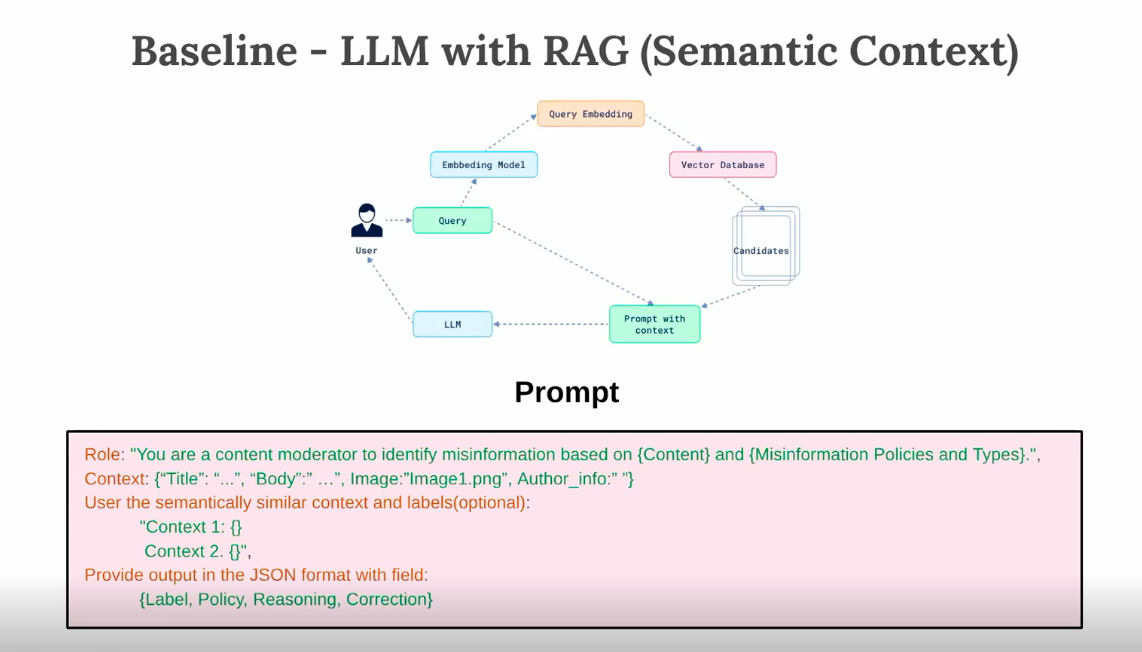
- An obvious first baseline would be to use RAG. So, where does this fall short?
- User posts are pretty short.
- Retrieval is hard here.
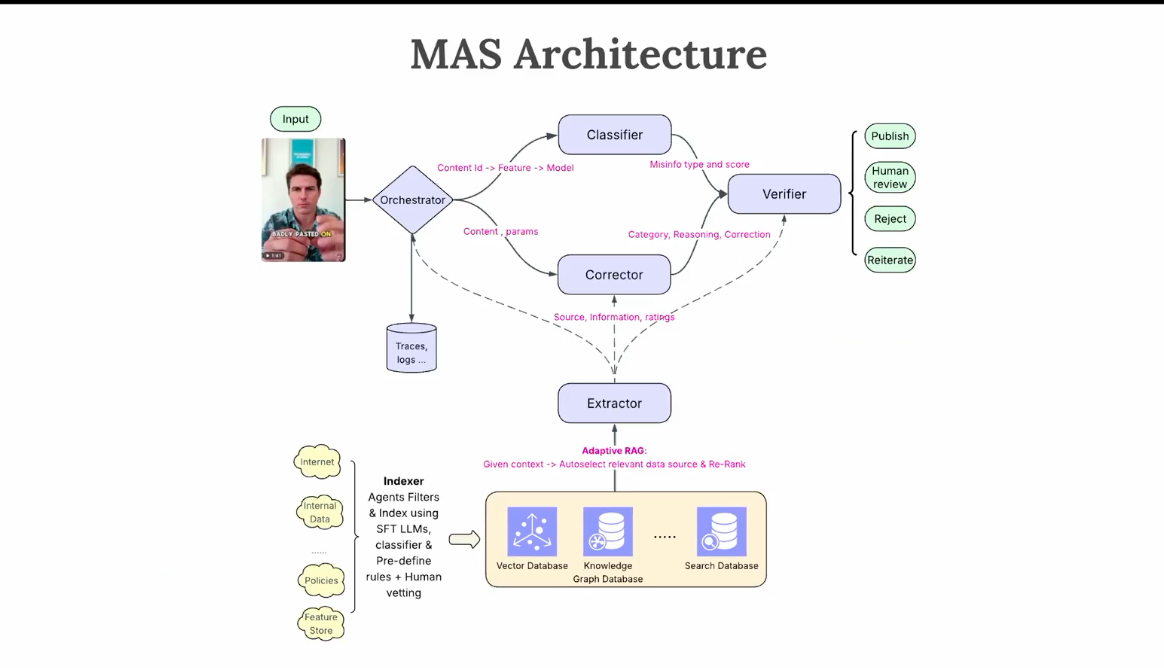
- For this problem, we can try multi-agent systems:
- Pros:
- Efficient and scalable
- Policies and logic encoded as separate agents
- Cons:
- High cost and latency
- Complex
- Coordination is hard
- Agent systems can be brittle
- Pros:
Talk 6: When AI Agents Argue: Structured Dissent Patterns for Production Reliability
Talk 6 Abstract
Single-agent LLM systems fail silently in production - they’re confidently wrong at scale with no mechanism for self-correction. We’ve deployed a multi-agent orchestration pattern called ““structured dissent”” where believer, skeptic, and neutral agents debate decisions before consensus. This isn’t theoretical - we’ll show production deployment patterns, cost/performance tradeoffs, and measurable reliability improvements. You’ll learn when multi-agent architectures justify the overhead, how to orchestrate adversarial agents effectively, and operational patterns for monitoring agent reasoning quality in production.
Our first deployment of the debate swarm revolves around MCP servers - we use a security swarm specially built for MCP servers to analyze findings from open source security tools. This provides more nuanced reasoning and gives a confidence score to evaluate the security of unknown MCP tools.
Talk 6 Notes
They’ve also written about this topic in a good blog post (they’ve also written other posts about this topic as well).
I like the idea of adversial AI agents that can push back on each other, and I often do this in my own workflows as well, where I have AI personas that give me fine-grained specific feedback and commentary, and I often pair them with an instruction requiring them to give critical and often adversarial feedback.
Overall takeaways
- The field is getting mature enough that different fields are starting to diverge. Considerations in voice AI, for example, are different than those working in MCP servers, which are different from those working in AI adoption in the workplace.
- Give people the training and guardrails to start experimenting with AI agents themselves and you’ll be surprised about what they come up with. Before LLMs, any AI applications had to be funneled to a dedicated ML team, taking a long time to shp anything user-facing, but now a nontechnical person can hack on a 1-2 day project and build a sophisticated agent that automates away an important part of their job.
- Good software engineering principles never go out of date: AIOps piggybacks on top of MLOps, which itself piggybacks on top of Ops. Get your telemetry figured out, define your software development life cycle (SDLC), have measures (both quantitative AND qualitative) for success, and stay close to the customer use case.
- Traditional unit tests are great, but AI agents break that traditional test-driven-development model. Create your evals suite, define your “golden path” user journeys, and see just how creative people end up interfacing with your AI agents and all the wonderful ways it can break.
- AI lets you ship quicker, which lets you see that code was never the bottleneck for a software business.
- Customer expectations are much higher now as AI models continue to improve. For cases like voice AI, this is especially true, as people are expecting lower-latency applications and something closer to real-time interaction. Related: 99.999% accuracy is becoming more table stakes and customers are starting to expect it. People don’t care that it’s AI, they care that their problems are solved, and this is becoming more true as agentic AI becomes more widely adopted and socially ingrained.