
What I’m learning (2024-05-14)
What I’m Learning (2024-05-14 edition)
Machine learning
- The new GPT4o model just dropped. I like that this drop is a lot more product and usability-focused, rather than just improving the accuracy on certain benchmarks. It is better than GPT4 on benchmarks, but a lot of the value seems to be that it is natively multimodal and is much faster than the original GPT4. Exciting!
Software engineering
- “It feels like Bluesky has missed its moment” Interesting thread on whether Bluesky is the “right” paradigm for the future of social media. Bluesky is definitely very opinionated in how it’s being built (for example, composability and decentralization are core principles of the platform) and the developers are working not only on Bluesky, but also in supporting the foundation for a general decentralized ecosystem. I think we’re seeing the growing pains of a social platform in real time, and that’s OK. There seems to be a very vocal and active subset of users on Bluesky, and there are definitely prominent and distinct communities on the platform. I’m not sure what “making it” would even entail in the first place, and I don’t think that Bluesky has to replace Twitter in order to be successful. I like the direction that Bluesky is heading and the 2024 product roadmap is really promising.
- “Scaling the Instagram Explore recommendations system”
A good writeup on the high level design of Instagram’s “Explore” recommendation algorithm. It looks like they break down the recommendation system into 4 parts:
-
Retrieval: The purpose of retrieval is to fetch the possible posts that will be ranked the most highly in later stages if all the posts were ranked. It’s impossible to rank all posts for all users, so a retrieval step helps narrow down the billions of possible posts into a subset of, for example, a few dozen or hundred. Instagram uses four main types of sources for retrieval:
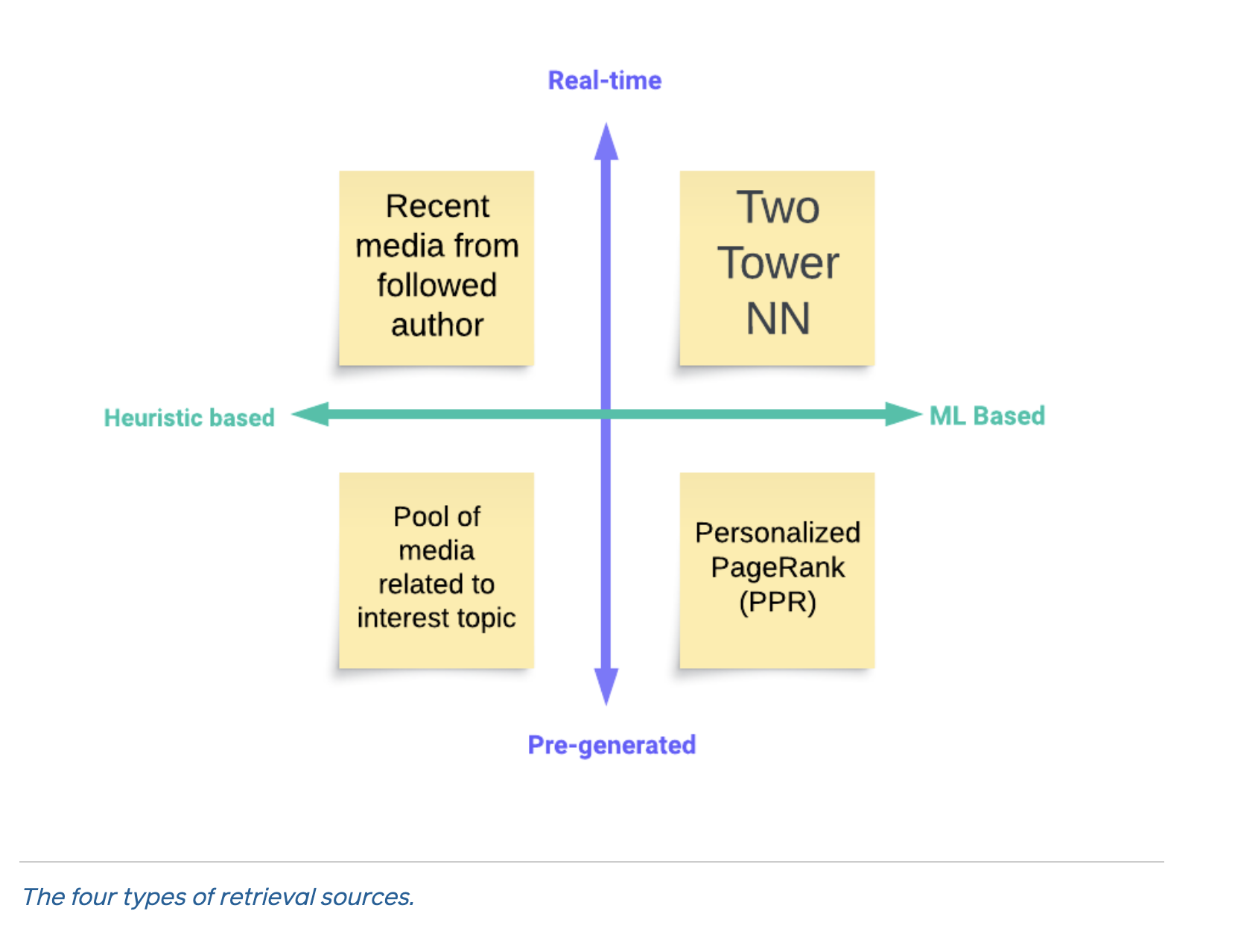 The post highlights two specific retrieval methods:
1. Two-tower networks: Two-tower networks are used to model joint user-item preferences and map them to the same embedding space. The idea is that by training both user and post features together and optimizing for predicting the probability that the user engages with said post, user embeddings should exist near relevant item embeddings in the embedding space. Then, Instagram stores the embeddings using a service such as FAISS so that they can quickly fetch results. During online retrieval, the recommendation algorithm fetches the latest user features, maps that to an embedding, and then searches the embedding space to get related items whose embeddings are close to the user’s embedding. The blog makes sure to note that the two-tower network model can’t directly consume user-item interactions (which are usually the most powerful features and the ones most commonly used in, say, collaborative filtering) since doing so loses the ability to provide logically distinct and separate user and item embeddings.
2. User interaction history: The item embeddings generated from the two-tower networks can also be used to directly compare a set of posts against the posts that a user has liked or engaged with in the past. I personally like the explainability of this approach more than regular two-tower inference since we can more easily compare the similarity of two posts than we can compare the compatibility of a post and a user’s characteristics.
The post highlights two specific retrieval methods:
1. Two-tower networks: Two-tower networks are used to model joint user-item preferences and map them to the same embedding space. The idea is that by training both user and post features together and optimizing for predicting the probability that the user engages with said post, user embeddings should exist near relevant item embeddings in the embedding space. Then, Instagram stores the embeddings using a service such as FAISS so that they can quickly fetch results. During online retrieval, the recommendation algorithm fetches the latest user features, maps that to an embedding, and then searches the embedding space to get related items whose embeddings are close to the user’s embedding. The blog makes sure to note that the two-tower network model can’t directly consume user-item interactions (which are usually the most powerful features and the ones most commonly used in, say, collaborative filtering) since doing so loses the ability to provide logically distinct and separate user and item embeddings.
2. User interaction history: The item embeddings generated from the two-tower networks can also be used to directly compare a set of posts against the posts that a user has liked or engaged with in the past. I personally like the explainability of this approach more than regular two-tower inference since we can more easily compare the similarity of two posts than we can compare the compatibility of a post and a user’s characteristics. - First pass of ranking: A lightweight, computationally less intensive model ranks the thousands of candidates from retrieval and returns hundreds. The model in this stage is a neural network that is trained to predict the output of the second stage of ranking. This, as the blog notes, is akin to “knowledge distillation” from the more powerful second model to the more lighweight first model.
- Second pass of ranking: The second pass of the ranking is more compute-heavy and is a multi-task multi label (MTML) neural network model that predicts the probability of a click, like, etc.
According to the blog post, their value equation is:
Expected Value = W_click * P(click) + W_like * P(like) – W_see_less * P(see less) + etc.Practically, it seems like the team computes these feeds offline due to the computational constraints of the model. - Final reranking: Like in most recommendation algorithms, the Instagram Explore feed has a final reranking and curation step. They manually filter content, re-order items based on business logic, and more quality-of-life improvements.
Obviously, the blog post is pretty high-level and the secret sauce is in all the engineering that makes it all happen. But it’s a great overview nonetheless, and as complex as the algorithm surely is, it’s nice to see that it can still be clearly articulated in this type of easy-to-digest blog post.
-
- “Ask & Adjust: The Future of Productivity Interfaces” I like the emphasis on productivity interfaces (Notion, Figma, Google Docs, etc.) being eventually collaborative human-AI interfaces. We’ve already been naturally progressing in this direction, where, as the blog points out, we’ve gone from “DIY” to “here are templates to make DIY easier”, and the next logical step is having AI create a template for you and you can DIY as much as you want (or ask the AI to make changes for you). For example, I would get pretty far just by asking an AI assistant to create the outline of a presentation about the history of NLP. I would have to fill in the blanks myself and validate, but AI can do a great job in creating the initial slides, an outline for the talk, key points, and things like that. Does this mean that AI automates people doing this creation? I don’t think so. As the author of the blog points out, “for the applications I’m talking about (VSCode, Figma, Webflow, Notion, Warp and the like) we are often unable to express our intentions to AI precisely enough for an AI to get it completely right, even through repeated prompting”, so it’s clear that even with AI assistance there is still a place for human expertise. I suppose AI will make it easier to get to the “hard stuff” that we likely care more about building anyways, which is a recurring message in AI it seems.
Research
- “How persuasive is AI-generated propaganda?” Brief piece on using GPT3 to create propaganda. As expected, GPT3 does quite well at writing propaganda pieces, as well as existing propaganda pieces, and also helps human-machine teams write high-quality propaganda efficiently (with the humans serving to tweak/tune the LLM outputs). I suppose this reduces the language barrier for foreign entities to spam propaganda into US social media feeds. This also has implications for spammers who can now write higher quality phishing content. Plus, as the paper notes, the cost of writing propaganda content is asymptotically approaching the cost of a ChatGPT subscription. But one can argue though that we don’t really explicitly need AI-generated propaganda to convince people of a certain point of view. Past research has shown that in fact just casting doubt is often enough of a gateway to get people to doubt credible information and be more open to conspiracy theories.
- “ANTHROSCORE: A Computational Linguistic Measure of Anthropomorphism” A paper that looks at the change in anthropomorphic descriptions of NLP models over time. I suppose that logically it makes sense for NLP papers and popular media to be increasingly anthropomorphic in their descriptions of what models can do. It also makes sense that media coverage is much more anthropomorphic than research papers. I suppose that it’s hard to describe incremental progress in the abilities of models without slipping into anthropomorphic language, since the actual baseline is human performance. Comprehension and manipulation of language is such a core human trait that as a machine better and better approximates human levels of language, they seem to become “more human”. For example, as the paper notes, “anthropomorphism is embedded into the way that researchers conceptualize, discuss, and interact with their objects of study. In NLP, for instance, evaluation benchmarks involve directly comparing LMs’ performance to humans on cognition- and behavior-based tasks like answering questions and writing stories…”. It’s hard to remind people that these are machines and not humans, but then again, if tech people can’t agree on what separates human vs. machine intelligence, how can non-technical people make that distinction?
Personal:
- I’ve started going back to the gym again and I feel like my energy has come back dramatically. Turns out doing the basics like taking care of your health do go a long way?
- I’ve started a digital detox of sorts, turning off my phone during the day and using it in the evening as an alarm clock. It’s so easy to lose 20 minutes in the blink of an eye just from scrolling on IG reels; I fear the power of the recommendation algorithm.