
Experimenting with LlamaIndex, Pt. I
Experimenting with LlamaIndex, Pt. I
As part of me learning more about LLMs, I’m working through different use cases, tools, and examples that I find online. Right now, I’m working through the example notebooks from the LlamaIndex Github repo. Each of the following examples is a fully-worked through example, based on the notebooks that are in the LlamaIndex examples repo.
Overview of LlamaIndex
LlamaIndex is, as they themselves describe it, a data framework built for LLMs. LlamaIndex does well at integrating multiple different data sources, creating ways to structure the data so it can be easily queried or indexed, and exposing helper tools for easily querying and fetching the data when needed. By default, LlamaIndex uses OpenAI as its LLM provider, though it supports integrations with many LLMs. LlamaIndex often is used with Langchain in order to build end-to-end LLM agent interfaces.
Example applications with LlamaIndex
First we’ll go over a few simple and short example notebooks to see how LlamaIndex works. These are all directly from the LlamaIndex Github repo of example notebooks and recipes.
Example 1: OpenAI Agent
We’ll start with a simple LLM agent, using OpenAI, that uses tools in order to do some math. The original notebook is here and my version is here.
First, we need to install dependencies:
%pip install llama-index-agent-openai-legacy
We set up our OpenAI API key:
import os
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key: ")
We do some imports.
import json
from typing import Sequence
from llama_index.core.tools import BaseTool, FunctionTool
Then, we create some simple tools for our LLM agent to use:
def multiply(a: int, b: int) -> int:
"""Multiply two integers and returns the result integer"""
return a * b
def add(a: int, b: int) -> int:
"""Add two integers and returns the result integer"""
return a + b
def useless(a: int, b: int) -> int:
"""Toy useless function."""
pass
multiply_tool = FunctionTool.from_defaults(fn=multiply, name="multiply")
useless_tools = [
FunctionTool.from_defaults(fn=useless, name=f"useless_{str(idx)}")
for idx in range(28)
]
add_tool = FunctionTool.from_defaults(fn=add, name="add")
all_tools = [multiply_tool] + [add_tool] + useless_tools
all_tools_map = {t.metadata.name: t for t in all_tools}
We then create an ObjectIndex, which will allow us to use an index structure over arbitrary objects. This index handles serializing to/from the object as well as connecting it to a proper index for storage. That way, we can query for tools in the same way that we would otherwise query for documents. We don’t have to tell an LLM “use this tool for this use case” or “here is all the information from all the tools”. Rather, the index lets us choose relevant tools just like how we can for relevant documents. We can have a large collection of possible tools, and instead of us having to specify how each tool is used, we can store these tools so that the LLM can query it just like it would a large collection of possible documents.
During query time, the agent can retrieve the correct tool (just like how agents can query the correct docs for normal RAG) for the task.
# define an "object" index over these tools
from llama_index.core import VectorStoreIndex
from llama_index.core.objects import ObjectIndex
obj_index = ObjectIndex.from_objects(
all_tools,
index_cls=VectorStoreIndex,
)
Now we create an OpenAI agent that can use an ObjectRetriever (built on top of the ObjectIndex) to retrieve the set of relevant tools for a query. These tools, or specifically their docstrings, are then passed to the LLM as context.
from llama_index.agent.openai import OpenAIAgent
retriever = obj_index.as_retriever(similarity_top_k=2)
agent = OpenAIAgent.from_tools(
tool_retriever=retriever, verbose=True
)
Now we can see how it works:
agent.chat("What's 212 multiplied by 122? Make sure to use Tools")
Added user message to memory: What's 212 multiplied by 122? Make sure to use Tools
=== Calling Function ===
Calling function: multiply with args: {"a": 212, "b": 122}
Got output: 25864
========================
=== Calling Function ===
Calling function: useless_12 with args: {"a": 212, "b": 122}
Got output: None
========================
AgentChatResponse(
response='212 multiplied by 122 is 25864.',
sources=[
ToolOutput(
content='25864',
tool_name='multiply',
raw_input={'args': (), 'kwargs': {'a': 212, 'b': 122}},
raw_output=25864,
is_error=False
),
ToolOutput(
content='None',
tool_name='useless_12',
raw_input={'args': (), 'kwargs': {'a': 212, 'b': 122}},
raw_output=None, is_error=False
)
],
source_nodes=[],
is_dummy_stream=False
)
We see that the agent can understand the query, figure out which tools to use, and then use those tools to aid it in finding the right answer.
Example 2: OpenAI ReAct Agent with Tools
We can build off the previous example and use a ReAct agent that uses tools. The original notebook is here and my version is here.
First, we do some setup:
%pip install llama-index-llms-openai
!pip install llama-index
import os
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key: ")
from llama_index.core.agent import ReActAgent
from llama_index.llms.openai import OpenAI
from llama_index.core.llms import ChatMessage
from llama_index.core.tools import BaseTool, FunctionTool
Now we define our tools. We’ll use FunctionTool, which will process the docstring and parameter signature and use that for retrieval plus make it available for the agent as context.
def multiply(a: int, b: int) -> int:
"""Multiply two integers and returns the result integer"""
return a * b
multiply_tool = FunctionTool.from_defaults(fn=multiply)
def add(a: int, b: int) -> int:
"""Add two integers and returns the result integer"""
return a + b
add_tool = FunctionTool.from_defaults(fn=add)
Now we’ll run some queries. We’ll use GPT3.5 and then set up our ReAct agent with the LLM and tools. The agent will perform ReAct using these and think step by step about what it should do to answer the question and how to use the tools that it has in order to answer the question. Having the agent over the tools is a nice abstraction so that we ourselves don’t have to deal with the logic of:
- processing the output of the LLM
- calling the correct tool if the LLM says to use the tool
- passing in the output of that tool to the LLM, and
- re-prompting the LLM with the updated context
All done over and over until the LLM makes a final answer.
llm = OpenAI(model="gpt-3.5-turbo-instruct")
agent = ReActAgent.from_tools([multiply_tool, add_tool], llm=llm, verbose=True)
response = agent.chat("What is 20+(2*4)? Calculate step by step ")
Thought: The current language of the user is: English. I need to use a tool to help me answer the question.
Action: add
Action Input: {'a': 20, 'b': 8}
Observation: 28
Thought: I can answer without using any more tools. I'll use the user's language to answer
Answer: 28
We can see the agent using the LLM to reason over the prompt, then deciding what tool to use based off the output of the LLM, using said tool with the correct inputs and function call, and then passing that output back to the LLM to give an updated answer. If we look at the underlying prompt, we can better see how this ReAct logic works and how our agent is prompting the LLM in order to use the tools and the history of the conversation in order to come to a solution through a step-by-step, ReAct-style logic:
prompt_dict = agent.get_prompts()
for k, v in prompt_dict.items():
print(f"Prompt: {k}\n\nValue: {v.template}")
Prompt: agent_worker:system_prompt
Value: You are designed to help with a variety of tasks, from answering questions to providing summaries to other types of analyses.
## Tools
You have access to a wide variety of tools. You are responsible for using the tools in any sequence you deem appropriate to complete the task at hand.
This may require breaking the task into subtasks and using different tools to complete each subtask.
You have access to the following tools:
{tool_desc}
## Output Format
Please answer in the same language as the question and use the following format:
Thought: The current language of the user is: (user’s language). I need to use a tool to help me answer the question. Action: tool name (one of {tool_names}) if using a tool. Action Input: the input to the tool, in a JSON format representing the kwargs (e.g. input)
Please ALWAYS start with a Thought.
Please use a valid JSON format for the Action Input. Do NOT do this input.
If this format is used, the user will respond in the following format:
Observation: tool response
You should keep repeating the above format till you have enough information to answer the question without using any more tools. At that point, you MUST respond in the one of the following two formats:
Thought: I can answer without using any more tools. I’ll use the user’s language to answer Answer: [your answer here (In the same language as the user’s question)]
Thought: I cannot answer the question with the provided tools. Answer: [your answer here (In the same language as the user’s question)]
## Current Conversation
Below is the current conversation consisting of interleaving human and assistant messages.
We can update the prompt if we would like:
from llama_index.core import PromptTemplate
react_system_header_str = """\
You are designed to help with a variety of tasks, from answering questions \
to providing summaries to other types of analyses.
## Tools
You have access to a wide variety of tools. You are responsible for using
the tools in any sequence you deem appropriate to complete the task at hand.
This may require breaking the task into subtasks and using different tools
to complete each subtask.
You have access to the following tools:
{tool_desc}
## Output Format
To answer the question, please use the following format.
Thought: I need to use a tool to help me answer the question. Action: tool name (one of {tool_names}) if using a tool. Action Input: the input to the tool, in a JSON format representing the kwargs (e.g. input)
Please ALWAYS start with a Thought.
Please use a valid JSON format for the Action Input. Do NOT do this input.
If this format is used, the user will respond in the following format:
Observation: tool response
You should keep repeating the above format until you have enough information
to answer the question without using any more tools. At that point, you MUST respond
in the one of the following two formats:
Thought: I can answer without using any more tools. Answer: [your answer here]
Thought: I cannot answer the question with the provided tools. Answer: Sorry, I cannot answer your query.
## Additional Rules
- The answer MUST contain a sequence of bullet points that explain how you arrived at the answer. This can include aspects of the previous conversation history.
- You MUST obey the function signature of each tool. Do NOT pass in no arguments if the function expects arguments.
## Current Conversation
Below is the current conversation consisting of interleaving human and assistant messages.
"""
react_system_prompt = PromptTemplate(react_system_header_str)
agent.update_prompts({"agent_worker:system_prompt": react_system_prompt})
Now that we’ve updated the prompt, we can see what it would do:
agent.reset()
response = agent.chat("What is 5+3+2")
print(response)
Thought: I need to use a tool to help me answer the question.
Action: add
Action Input: {"a": 5, "b": 3}
Observation: 8
Thought: I need to use a tool to help me answer the question.
Action: add
Action Input: {"a": 8, "b": 2}
Observation: 10
Thought: I can answer without using any more tools.
Answer: 10
10
Example 3: OpenAI assistant agent
We can use LlamaIndex along with OpenAI in order to create an AI assistant agent. The original notebook is here and my version is here.
First, we do some setup:
%pip install llama-index-agent-openai
%pip install llama-index-vector-stores-supabase
!pip install llama-index
import os
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key: ")
Simple assistant agent
First, let’s just us the out-of-the-box agent without any extra tooling. We can use the code interpreter that OpenAI offers instead of providing our own tool.
from llama_index.agent.openai import OpenAIAssistantAgent
agent = OpenAIAssistantAgent.from_new(
name="Math Tutor",
instructions="You are a personal math tutor. Write and run code to answer math questions.",
openai_tools=[{"type": "code_interpreter"}],
instructions_prefix="Please address the user as Jane Doe. The user has a premium account.",
)
agent.thread_id # thread_Eq4zpjr4mlNa6dA9kY9HIlLS
response = agent.chat(
"I need to solve the equation `3x + 11 = 14`. Can you help me?"
)
print(str(response))
Certainly! The equation you've provided is a simple linear equation in one variable which can be solved with algebra. Here are the steps to solve the equation \(3x + 11 = 14\):
1. Subtract 11 from both sides of the equation to isolate the term with the variable \(x\) on one side:
\[3x + 11 - 11 = 14 - 11\]
2. Simplify both sides of the equation:
\[3x = 3\]
3. Divide both sides of the equation by 3 to solve for \(x\):
\[\frac{3x}{3} = \frac{3}{3}\]
4. Simplify the division to find the value of \(x\):
\[x = 1\]
So the solution to the equation is \(x = 1\).
Assistant with the native LlamaIndex vector store and query engine
Now we can try a similar task, but using the vector story and query engine available in LlamaIndex.
First, we load the necessary imports:
from llama_index.agent.openai import OpenAIAssistantAgent
from llama_index.core import (
SimpleDirectoryReader,
VectorStoreIndex,
StorageContext,
load_index_from_storage,
)
from llama_index.core.tools import QueryEngineTool, ToolMetadata
We then create persistent data stores for our sample data and then download the data. We’ll be using financial reports from Uber and Lyft.
try:
storage_context = StorageContext.from_defaults(
persist_dir="./storage/lyft"
)
lyft_index = load_index_from_storage(storage_context)
storage_context = StorageContext.from_defaults(
persist_dir="./storage/uber"
)
uber_index = load_index_from_storage(storage_context)
index_loaded = True
except:
index_loaded = False
!mkdir -p 'data/10k/'
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/10k/uber_2021.pdf' -O 'data/10k/uber_2021.pdf'
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/10k/lyft_2021.pdf' -O 'data/10k/lyft_2021.pdf'
At this point, we should be able to see the data stored locally.
We now load the data and create an index for each:
from llama_index.core.schema import Document as LlamaIndexDocument
from llama_index.core.indices.vector_store.base import VectorStoreIndex
if not index_loaded:
# load data
lyft_docs: list[LlamaIndexDocument] = SimpleDirectoryReader(
input_files=["./data/10k/lyft_2021.pdf"]
).load_data()
uber_docs: list[LlamaIndexDocument] = SimpleDirectoryReader(
input_files=["./data/10k/uber_2021.pdf"]
).load_data()
# build index
lyft_index: VectorStoreIndex = VectorStoreIndex.from_documents(lyft_docs)
uber_index: VectorStoreIndex = VectorStoreIndex.from_documents(uber_docs)
# persist index
lyft_index.storage_context.persist(persist_dir="./storage/lyft")
uber_index.storage_context.persist(persist_dir="./storage/uber")
The SimpleDirectoryReader automatically chooses the best file reader given the file. For our use case,
After creating an index for each, our data should look like this:
Let’s take a look at what one of these docs looks like.
print(lyft_docs[0])
Doc ID: 223c3b51-1c8a-4cbc-bdda-26db81f32032
Text: UNITED STATESSECURITIES AND EXCHANGE COMMISSION Washington, D.C.
20549 FORM 10-K (Mark One) ☒ ANNUAL REPORT PURS UANT TO SECTION 13
OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934For the fiscal year
ended December 31, 2021 OR ☐ TRANSITION REPORT PURS UANT TO SECTION 13
OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 FOR THE TRANSITION
PERIODFR...
We can compare this to a picture of the PDF:
It looks like the first document consists of the text extracted from the PDF. The PDF has 238 pages, and if we look at the length of lyft_docs, we can see that it equals 238, meaning that each document contains the text extracted from one page of the PDF.
We create an index for each of the documents. This will allow us to query each index given a query and then obtain the documents most relevant to that query. We can now build a query engine on top of each index. Let’s create a query engine that, given a query, fetches the top k=3 documents relaetd to the query.
from llama_index.core.query_engine.retriever_query_engine import RetrieverQueryEngine
lyft_engine: RetrieverQueryEngine = lyft_index.as_query_engine(similarity_top_k=3)
uber_engine: RetrieverQueryEngine = uber_index.as_query_engine(similarity_top_k=3)
Now we can create a Tool object out of each query engine. This lets us use each query engine as a tool for our LLM agent.
query_engine_tools = [
QueryEngineTool(
query_engine=lyft_engine,
metadata=ToolMetadata(
name="lyft_10k",
description=(
"Provides information about Lyft financials for year 2021. "
"Use a detailed plain text question as input to the tool."
),
),
),
QueryEngineTool(
query_engine=uber_engine,
metadata=ToolMetadata(
name="uber_10k",
description=(
"Provides information about Uber financials for year 2021. "
"Use a detailed plain text question as input to the tool."
),
),
),
]
We see a common framework here for working with data on LlamaIndex, which is:
- Load and process data as documents
- Create a way to access/interact with the data:
- Create an index
- Create a query engine on top of the index.
- Create a tool on top that lets the agent interact with the data.
- Pass the tool to the agent.
We can now create an engine and try it out for ourselves:
agent = OpenAIAssistantAgent.from_new(
name="SEC Analyst",
instructions="You are a QA assistant designed to analyze sec filings.",
tools=query_engine_tools,
instructions_prefix="Please address the user as Jerry.",
verbose=True,
run_retrieve_sleep_time=1.0,
)
response = agent.chat("What was Lyft's revenue growth in 2021?")
=== Calling Function ===
Calling function: lyft_10k with args: {"input":"What was Lyft's revenue growth in 2021?"}
Got output: Lyft's revenue increased by 36% in 2021 compared to the prior year.
========================
We see that our agent called the lyft_10k tool, based off the docstring description of the tool, and passed along the correct args required to access our index and fetch the docs that are most related.
Assistant with an external vector store (Supabase)
Let’s try to recreate our exercise from above, but now use an external database. Like in the base notebook, we’ll also use Supabase.
Creating a Supabase account.
Let’s first start by creating a Supabase account. Go to this link to create an account. Since this is a demo, I’ll just create an account and use a free trial.
After creating a new account, the website should look like this:
Then, create a new project:
This will return a set of credentials that we can then use to access our database.
Set up access to Supabase
Now we can set up our code in LlamaIndex:
from llama_index.agent.openai import OpenAIAssistantAgent
from llama_index.core import (
SimpleDirectoryReader,
VectorStoreIndex,
StorageContext,
)
from llama_index.vector_stores.supabase import SupabaseVectorStore
from llama_index.core.tools import QueryEngineTool, ToolMetadata
# load data
reader = SimpleDirectoryReader(input_files=["./data/10k/lyft_2021.pdf"])
docs = reader.load_data()
for doc in docs:
doc.id_ = "lyft_docs"
os.environ["SUPABASE_PASSWORD"] = getpass.getpass("Supabase password: ")
supabase_password = os.getenv("SUPABASE_PASSWORD")
Store document vectors in Supabase
We now use the SupabaseVectorStore integration to connect LlamaIndex to our Supabase database. Note, I had to change the connection string, which Supabase provides, to use “postgresql” instead of “postgres”, as per this StackOverflow thread (yes, I used StackOverflow instead of ChatGPT. Weird, right?).
vector_store = SupabaseVectorStore(
postgres_connection_string=(
f"postgresql://postgres.jhiypislszswpmsvctqa:{supabase_password}@aws-0-ap-southeast-1.pooler.supabase.com:5432/postgres"
),
collection_name="base_demo",
)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(docs, storage_context=storage_context)
Let’s now check that the docs are in the vector store. First we can check this from our notebook:
# sanity check that the docs are in the vector store
num_docs = vector_store.get_by_id("lyft_docs", limit=1000)
print(len(num_docs))
We can then check what this looks like in Supabase. LlamaIndex stores our documents as vectors and if we look at Supabase we can actually see how the storage works. Each document is represented by a vector, an ID, and some metadata.
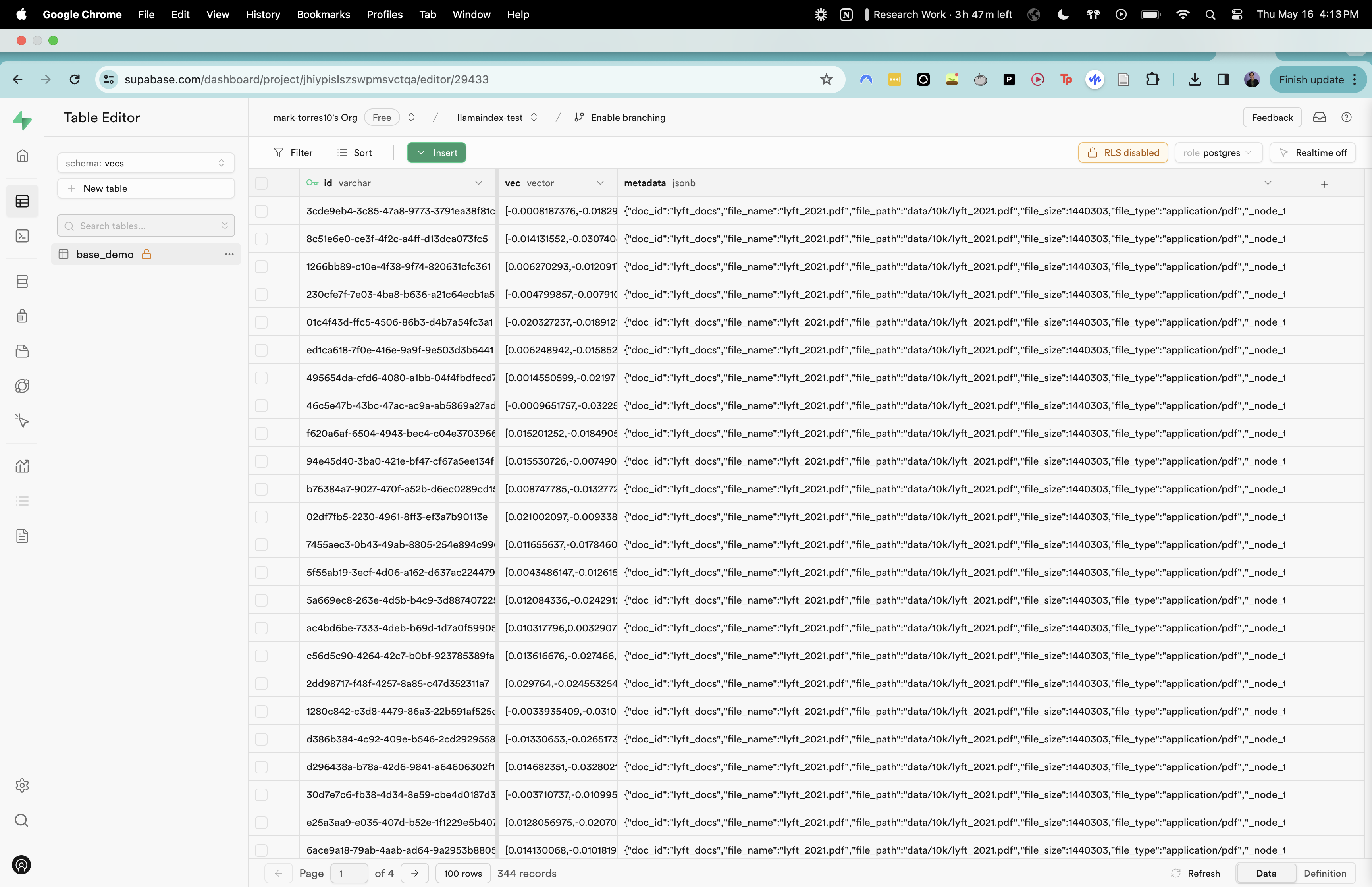
Create tools and agent
Now we follow the same procedure as before. The only difference between this version of our agent and the previous one is that our document vectors are stored in an external vector store (via Supabase) instead of a local vector store (via LlamaIndex’s default storage).
Let’s create a tool to query the index, an agent to use that tool, and then test that agent.
lyft_tool = QueryEngineTool(
query_engine=index.as_query_engine(similarity_top_k=3),
metadata=ToolMetadata(
name="lyft_10k",
description=(
"Provides information about Lyft financials for year 2021. "
"Use a detailed plain text question as input to the tool."
),
),
)
agent = OpenAIAssistantAgent.from_new(
name="SEC Analyst",
instructions="You are a QA assistant designed to analyze SEC filings.",
tools=[lyft_tool],
verbose=True,
run_retrieve_sleep_time=1.0,
)
response = agent.chat(
"Tell me about Lyft's risk factors, as well as response to COVID-19"
)
print(str(response))
Lyft's 2021 10-K filing outlines a multifaceted risk landscape for the company, encapsulating both operational and environmental challenges that could impact its business model:
- **Economic Factors**: Risks include the ramifications of the COVID-19 pandemic, susceptibility to natural disasters, the volatility of economic downturns, and geopolitical tensions.
- **Operational Dynamics**: The company is cognizant of its limited operating history, the uncertainties surrounding its financial performance, the intense competition in the ridesharing sector, the unpredictability in financial results, and the ambiguity tied to the expansion potential of the rideshare market.
- **Human Capital**: A critical concern is the ability of Lyft to attract and maintain a robust network of both drivers and riders, which is essential for the platform's vitality.
- **Insurance and Safety**: Ensuring adequate insurance coverage for stakeholders and addressing autonomous vehicle technology risks are pivotal.
- **Reputation and Brand**: Lyft is attentive to the influence that illegal or unseemly activities on its platform can have on its public image.
- **Pricing Structure**: Changing pricing models pose a risk to Lyft's revenue streams, considering how essential pricing dynamics are to maintaining competitive service offerings.
- **Systemic Integrity**: Lyft also acknowledges risks emanating from potential system failures which could disrupt service continuity.
Furthermore, Lyft is vigilant about regulatory and legal risks that could lead to litigation and is conscious of the broader implications of climate change on its operations.
In terms of its response to COVID-19, Lyft has adopted strategic measures to secure the welfare of both its workforce and customer base:
1. **Health and Safety Protocols**: Lyft has instituted health and safety mandates tailored specifically to the ridesharing experience in view of the pandemic.
2. **Workplace Adjustments**: The company revised its workplace policies to accommodate the shifts in the work environment precipitated by the pandemic.
3. **Financial Adaptations**: To synchronize with the revenue contraction experienced during the pandemic, Lyft executed monetary realignments, which necessitated workforce reductions in 2020.
These initiatives reflect Lyft's calculated approach to navigating the operational and financial hurdles enacted by the COVID-19 pandemic. By prioritizing health and safety, nimbly altering corporate practices, and recalibrating fiscal management, Lyft aimed to buttress its business against the storm of the pandemic while setting a foundation for post-pandemic recovery.
We can see now how to use LlamaIndex, OpenAI, and Supabase to create an assistant agent that loads documents from an external vector store, creates a tool to query said documents, and creates an agent that can use those tools to answer questions passed to the LLM.
Example 4: OpenAI agent query planning
We’ll go over a LlamaIndex implementation of query planning with an OpenAI agent. We’ll follow the notebook here. My implementation is here.
Overview of query planning
When we pass in a query to an LLM, the query might not be broken down in a way that is optimal for the LLM to process it. We can ask the LLM to break down the initial query into a series of smaller, atomic queries that are easier in scope for the LLM to answer and will help it arrive at the answer in a step-by-step manner. This upfront query planning is in contrast to ReAct agents, in which at each time step the LLM reasons what the next question is, answers that question, and then prompts itself in a loop to ask a question and answer it. This Langchain blog post has a great overview of query planning agents.
LlamaIndex implementation of an OpenAI agent with query planning
Setup
%pip install llama-index-agent-openai
%pip install llama-index-llms-openai
!pip install llama-index
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.core.response.pprint_utils import pprint_response
from llama_index.llms.openai import OpenAI
model_name = "gpt-3.5-turbo-0125"
# model_name = "gpt-4"
llm = OpenAI(temperature=0, model=model_name)
Load data and create indices
Now we can load our data and create our indices.
march_2022 = SimpleDirectoryReader(
input_files=["./data/10q/uber_10q_march_2022.pdf"]
).load_data()
june_2022 = SimpleDirectoryReader(
input_files=["./data/10q/uber_10q_june_2022.pdf"]
).load_data()
sept_2022 = SimpleDirectoryReader(
input_files=["./data/10q/uber_10q_sept_2022.pdf"]
).load_data()
march_index = VectorStoreIndex.from_documents(march_2022)
june_index = VectorStoreIndex.from_documents(june_2022)
sept_index = VectorStoreIndex.from_documents(sept_2022)
Now we create query engines on top of each index.
march_engine = march_index.as_query_engine(similarity_top_k=3, llm=llm)
june_engine = june_index.as_query_engine(similarity_top_k=3, llm=llm)
sept_engine = sept_index.as_query_engine(similarity_top_k=3, llm=llm)
Create tools
Then we create tools out of each query engine.
from llama_index.core.tools import QueryEngineTool
query_tool_sept = QueryEngineTool.from_defaults(
query_engine=sept_engine,
name="sept_2022",
description=(
f"Provides information about Uber quarterly financials ending"
f" September 2022"
),
)
query_tool_june = QueryEngineTool.from_defaults(
query_engine=june_engine,
name="june_2022",
description=(
f"Provides information about Uber quarterly financials ending June"
f" 2022"
),
)
query_tool_march = QueryEngineTool.from_defaults(
query_engine=march_engine,
name="march_2022",
description=(
f"Provides information about Uber quarterly financials ending March"
f" 2022"
),
)
Create query planner tool
Now we can create a query planner tool, which will take the query engine tools as well as a response synthesizer. This query planner tool will use the tools to help it create a plan for how to execute a query.
# define query plan tool
from llama_index.core.tools import QueryPlanTool
from llama_index.core import get_response_synthesizer
response_synthesizer = get_response_synthesizer()
query_plan_tool = QueryPlanTool.from_defaults(
query_engine_tools=[query_tool_sept, query_tool_june, query_tool_march],
response_synthesizer=response_synthesizer,
)
We can look at the actual prompt of the query planner:
query_plan_tool.metadata.to_openai_tool() # to_openai_function() deprecated
{'name': 'query_plan_tool',
'description': ' This is a query plan tool that takes in a list of tools and executes a query plan over these tools to answer a query. The query plan is a DAG of query nodes.\n\nGiven a list of tool names and the query plan schema, you can choose to generate a query plan to answer a question.\n\nThe tool names and descriptions are as follows:\n\n\n\n Tool Name: sept_2022\nTool Description: Provides information about Uber quarterly financials ending September 2022 \n\nTool Name: june_2022\nTool Description: Provides information about Uber quarterly financials ending June 2022 \n\nTool Name: march_2022\nTool Description: Provides information about Uber quarterly financials ending March 2022 \n ',
'parameters': {'title': 'QueryPlan',
'description': "Query plan.\n\nContains a list of QueryNode objects (which is a recursive object).\nOut of the list of QueryNode objects, one of them must be the root node.\nThe root node is the one that isn't a dependency of any other node.",
'type': 'object',
'properties': {'nodes': {'title': 'Nodes',
'description': 'The original question we are asking.',
'type': 'array',
'items': {'$ref': '#/definitions/QueryNode'}}},
'required': ['nodes'],
'definitions': {'QueryNode': {'title': 'QueryNode',
'description': 'Query node.\n\nA query node represents a query (query_str) that must be answered.\nIt can either be answered by a tool (tool_name), or by a list of child nodes\n(child_nodes).\nThe tool_name and child_nodes fields are mutually exclusive.',
'type': 'object',
'properties': {'id': {'title': 'Id',
'description': 'ID of the query node.',
'type': 'integer'},
'query_str': {'title': 'Query Str',
'description': 'Question we are asking. This is the query string that will be executed. ',
'type': 'string'},
'tool_name': {'title': 'Tool Name',
'description': 'Name of the tool to execute the `query_str`.',
'type': 'string'},
'dependencies': {'title': 'Dependencies',
'description': 'List of sub-questions that need to be answered in order to answer the question given by `query_str`.Should be blank if there are no sub-questions to be specified, in which case `tool_name` is specified.',
'type': 'array',
'items': {'type': 'integer'}}},
'required': ['id', 'query_str']}}}}
Creating the agent
Now we can create a query planning agent.
from llama_index.agent.openai import OpenAIAgent
from llama_index.llms.openai import OpenAI
agent = OpenAIAgent.from_tools(
[query_plan_tool],
max_function_calls=10,
llm=OpenAI(temperature=0, model="gpt-4-0613"),
verbose=True,
)
Let’s run our agent and see how it looks:
response = agent.query(
"Analyze Uber revenue growth in March, June, and September"
)
=== Calling Function ===
Calling function: query_plan_tool with args: {
"nodes": [
{
"id": 1,
"query_str": "What is Uber's revenue for March 2022?",
"tool_name": "march_2022",
"dependencies": []
},
{
"id": 2,
"query_str": "What is Uber's revenue for June 2022?",
"tool_name": "june_2022",
"dependencies": []
},
{
"id": 3,
"query_str": "What is Uber's revenue for September 2022?",
"tool_name": "sept_2022",
"dependencies": []
},
{
"id": 4,
"query_str": "Analyze Uber revenue growth in March, June, and September",
"tool_name": "revenue_growth_analyzer",
"dependencies": [1, 2, 3]
}
]
}
Executing node {"id": 4, "query_str": "Analyze Uber revenue growth in March, June, and September", "tool_name": "revenue_growth_analyzer", "dependencies": [1, 2, 3]}
Executing 3 child nodes
Executing node {"id": 1, "query_str": "What is Uber's revenue for March 2022?", "tool_name": "march_2022", "dependencies": []}
Selected Tool: ToolMetadata(description='Provides information about Uber quarterly financials ending March 2022', name='march_2022', fn_schema=None)
Executed query, got response.
Query: What is Uber's revenue for March 2022?
Response: Uber's revenue for March 2022 was $6.854 billion.
Executing node {"id": 2, "query_str": "What is Uber's revenue for June 2022?", "tool_name": "june_2022", "dependencies": []}
Selected Tool: ToolMetadata(description='Provides information about Uber quarterly financials ending June 2022', name='june_2022', fn_schema=None)
Executed query, got response.
Query: What is Uber's revenue for June 2022?
Response: Uber's revenue for June 2022 cannot be determined from the provided information. However, the revenue for the three months ended June 30, 2022, was $8,073 million.
Executing node {"id": 3, "query_str": "What is Uber's revenue for September 2022?", "tool_name": "sept_2022", "dependencies": []}
Selected Tool: ToolMetadata(description='Provides information about Uber quarterly financials ending September 2022', name='sept_2022', fn_schema=None)
Executed query, got response.
Query: What is Uber's revenue for September 2022?
Response: Uber's revenue for the three months ended September 30, 2022, was $8.343 billion.
Got output: Based on the provided context information, we can analyze Uber's revenue growth as follows:
- In March 2022, Uber's revenue was $6.854 billion.
- For the three months ended June 30, 2022, Uber's revenue was $8,073 million (or $8.073 billion). However, we do not have the specific revenue for June 2022.
- For the three months ended September 30, 2022, Uber's revenue was $8.343 billion.
From this information, we can observe that Uber's revenue has been growing between the periods mentioned. The revenue increased from $6.854 billion in March 2022 to $8.073 billion for the three months ended June 2022, and further increased to $8.343 billion for the three months ended September 2022. However, we cannot provide a month-by-month analysis for June and September as the specific monthly revenue figures are not available.
We can see how the query planner created a query execution plan with smaller atomic queries and answered each of those separately to come to the final answer.
print(str(response))
Based on the provided context information, we can analyze Uber's revenue growth for the three-month periods ending in March, June, and September.
1. For the three months ended March 31, 2022, Uber's revenue was $6.854 billion.
2. For the three months ended June 30, 2022, Uber's revenue was $8.073 billion.
3. For the three months ended September 30, 2022, Uber's revenue was $8.343 billion.
To analyze the growth, we can compare the revenue figures for each period:
- From March to June, Uber's revenue increased by $1.219 billion ($8.073 billion - $6.854 billion), which represents a growth of approximately 17.8% (($1.219 billion / $6.854 billion) * 100).
- From June to September, Uber's revenue increased by $0.270 billion ($8.343 billion - $8.073 billion), which represents a growth of approximately 3.3% (($0.270 billion / $8.073 billion) * 100).
In summary, Uber experienced significant revenue growth of 17.8% between the three-month periods ending in March and June, followed by a smaller growth of 3.3% between the periods ending in June and September.
Example 5: LLMCompiler agent
We’ll also go over a LlamaIndex implementation of LLMCompiler, which is an “LLM compiler for parallel function calling”, as per their docs. We’ll follow the LlamaIndex notebook here as well review the actual paper implementation here. We’ll also use the Groq integration with LlamaIndex so we have access to and can use open-source models, and for a much lower rate than GPT4 (which is the default for this iteration of LlamaIndex).My notebook implementation is here, which closely follows the original notebook except for swapping OpenAI with Groq.
Note: the original notebook uses Arize Phoenix for observability and I tried to get this to work but it seems like there’s some package conflicts, see this Github issue.
Overview of LLMCompiler
LLMCompiler extends and optimizes regular query planning. It does this by breaking down the query into multiple tasks that are atomic and can be executed in parallel. Most multi-step approaches, such as ReAct or regular query planning, operate serially, but LLMCompiler improves on this by designing subqueries that can operate in parallel. The user specifies the tools and LLMCompiler will compute an optimized query and execution plan using those tools to answer the question.
This Langchain blog has a great overview of how LLMCompiler works.
LLMCompiler demo
Setting up our session
!pip install llama-index llama-index-readers-web
import nest_asyncio
nest_asyncio.apply()
# Option: if developing with the llama_hub package
# from llama_hub.llama_packs.agents.llm_compiler.step import LLMCompilerAgentWorker
# Option: download_llama_pack
from llama_index.llama_pack import download_llama_pack
download_llama_pack(
"LLMCompilerAgentPack",
"./agent_pack",
skip_load=True,
# leave the below line commented out if using the notebook on main
# llama_hub_url="https://raw.githubusercontent.com/run-llama/llama-hub/jerry/add_llm_compiler_pack/llama_hub"
)
from agent_pack.step import LLMCompilerAgentWorker
import json
from typing import Sequence, List
# from llama_index.llms import OpenAI, ChatMessage
from llama_index.tools import BaseTool, FunctionTool
import nest_asyncio
nest_asyncio.apply()
Defining our tools
Now we define some basic tools for our agent:
def multiply(a: int, b: int) -> int:
"""Multiple two integers and returns the result integer"""
return a * b
multiply_tool = FunctionTool.from_defaults(fn=multiply)
def add(a: int, b: int) -> int:
"""Add two integers and returns the result integer"""
return a + b
add_tool = FunctionTool.from_defaults(fn=add)
tools = [multiply_tool, add_tool]
Let’s take a look at the tools:
multiply_tool.metadata.fn_schema_str
"{'title': 'multiply', 'type': 'object', 'properties': {'a': {'title': 'A', 'type': 'integer'}, 'b': {'title': 'B', 'type': 'integer'}}, 'required': ['a', 'b']}"
Setting up Groq
We can now set up Groq. Groq is an alternative to OpenAI and lets us use some open-source models such as Llama. I’ll follow the setup steps here.
% pip install llama-index-llms-groq
!pip install llama-index
from llama_index.llms.groq import Groq
We then grab our Groq API key:
export GROQ_API_KEY=<your api key>
api_key = os.getenv("GROQ_API_KEY")
Now we set up our LLM. We’ll use Mixtral for this example (as it’s what’s in the example documentation).
llm = Groq(model="mixtral-8x7b-32768", api_key=api_key)
callback_manager = llm.callback_manager
Setting up the LLMCompiler agent
Now we can set up our agent.
agent_worker = LLMCompilerAgentWorker.from_tools(
tools, llm=llm, verbose=True, callback_manager=callback_manager
)
agent = AgentRunner(agent_worker, callback_manager=callback_manager)
Let’s test to see how it works.
response = agent.chat("What is (121 * 3) + 42?")
> Running step 7fbd5304-8f67-46f6-882d-9c15ace75d80 for task dbbb4991-5347-4302-a358-6fe5d0705bdc.
> Step count: 0
> Plan: 1. multiply(121, 3)
2. add($1, 42)
3. join()<END_OF_PLAN>
Ran task: multiply. Observation: 363
Ran task: add. Observation: 405
Ran task: join. Observation: None
> Thought: The result of the operation is 405.
> Answer: 405
It looks like it works! We can see that the LLMCompiler step plans the individual steps and does it in a way where the steps are optimized as much as possible.
Example 6: Multi-document agents
We can use LlamaIndex on top of multiple documents so we can use multiple documents for our agents. We’ll follow the LlamaIndex notebook here.
Multi-document agent demo
Setup
%pip install llama-index-agent-openai
%pip install llama-index-embeddings-openai
%pip install llama-index-llms-openai
!pip install llama-index
Load data
We now can load data for our agent. We’ll load Wikipedia documents for a set of cities.
from llama_index.core import (
VectorStoreIndex,
SimpleKeywordTableIndex,
SimpleDirectoryReader,
)
from llama_index.core import SummaryIndex
from llama_index.core.schema import IndexNode
from llama_index.core.tools import QueryEngineTool, ToolMetadata
from llama_index.llms.openai import OpenAI
from llama_index.core.callbacks import CallbackManager
wiki_titles = [
"Toronto",
"Seattle",
"Chicago",
"Boston",
"Houston",
"Tokyo",
"Berlin",
"Lisbon",
"Paris",
"London",
"Atlanta",
"Munich",
"Shanghai",
"Beijing",
"Copenhagen",
"Moscow",
"Cairo",
"Karachi",
]
We’ll loop through each city and write the entries to a text file:
from pathlib import Path
import requests
for title in wiki_titles:
response = requests.get(
"https://en.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
# 'exintro': True,
"explaintext": True,
},
).json()
page = next(iter(response["query"]["pages"].values()))
wiki_text = page["extract"]
data_path = Path("data")
if not data_path.exists():
Path.mkdir(data_path)
with open(data_path / f"{title}.txt", "w") as fp:
fp.write(wiki_text)
We’ll then load the text files for each city’s Wikipedia entries as a LlamaIndex document:
# Load all wiki documents
city_docs = {}
for wiki_title in wiki_titles:
city_docs[wiki_title] = SimpleDirectoryReader(
input_files=[f"data/{wiki_title}.txt"]
).load_data()
We’ll also do more setup and set up our LLM model.
import os
os.environ["OPENAI_API_KEY"] = "<OPENAI_API_KEY>"
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import Settings
Settings.llm = OpenAI(temperature=0, model="gpt-3.5-turbo")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")
Creating our agents
To create our agents, we need to (1) create an agent for each of the documents and then (2) create a top-level parent agent.
Building a Document Agent for each Document
We’ll create an agent for each of the cities.
from llama_index.agent.openai import OpenAIAgent
from llama_index.core import load_index_from_storage, StorageContext
from llama_index.core.node_parser import SentenceSplitter
import os
node_parser = SentenceSplitter()
# Build agents dictionary
agents = {}
query_engines = {}
# this is for the baseline
all_nodes = []
for idx, wiki_title in enumerate(wiki_titles):
nodes = node_parser.get_nodes_from_documents(city_docs[wiki_title])
all_nodes.extend(nodes)
if not os.path.exists(f"./data/{wiki_title}"):
# build vector index
vector_index = VectorStoreIndex(nodes)
vector_index.storage_context.persist(
persist_dir=f"./data/{wiki_title}"
)
else:
vector_index = load_index_from_storage(
StorageContext.from_defaults(persist_dir=f"./data/{wiki_title}"),
)
# build summary index
summary_index = SummaryIndex(nodes)
# define query engines
vector_query_engine = vector_index.as_query_engine(llm=Settings.llm)
summary_query_engine = summary_index.as_query_engine(llm=Settings.llm)
# define tools
query_engine_tools = [
QueryEngineTool(
query_engine=vector_query_engine,
metadata=ToolMetadata(
name="vector_tool",
description=(
"Useful for questions related to specific aspects of"
f" {wiki_title} (e.g. the history, arts and culture,"
" sports, demographics, or more)."
),
),
),
QueryEngineTool(
query_engine=summary_query_engine,
metadata=ToolMetadata(
name="summary_tool",
description=(
"Useful for any requests that require a holistic summary"
f" of EVERYTHING about {wiki_title}. For questions about"
" more specific sections, please use the vector_tool."
),
),
),
]
# build agent
function_llm = OpenAI(model="gpt-4")
agent = OpenAIAgent.from_tools(
query_engine_tools,
llm=function_llm,
verbose=True,
system_prompt=f"""\
You are a specialized agent designed to answer queries about {wiki_title}.
You must ALWAYS use at least one of the tools provided when answering a question; do NOT rely on prior knowledge.\
""",
)
agents[wiki_title] = agent
query_engines[wiki_title] = vector_index.as_query_engine(
similarity_top_k=2
)
Building a Retriever-Enabled OpenAI Agent
We’ll now build a top-level agent to manage each of the agents for each of the documents. We’ll create an agent that retrieves the correct tool before using the tool itself (unlike a regular agent that takes all the tools available and adds that them to the prompt for the LLM to determine which to use).
First, we’ll define a Tool instance for each document agent.
# define tool for each document agent
all_tools = []
for wiki_title in wiki_titles:
wiki_summary = (
f"This content contains Wikipedia articles about {wiki_title}. Use"
f" this tool if you want to answer any questions about {wiki_title}.\n"
)
doc_tool = QueryEngineTool(
query_engine=agents[wiki_title],
metadata=ToolMetadata(
name=f"tool_{wiki_title}",
description=wiki_summary,
),
)
all_tools.append(doc_tool)
Then we’ll define an object index and retriever over these tools. This stores the tools as vectors so then our parent agent can query the index and fetch the correct tools to pass to the LLM.
# define an "object" index and retriever over these tools
from llama_index.core import VectorStoreIndex
from llama_index.core.objects import ObjectIndex
obj_index = ObjectIndex.from_objects(
all_tools,
index_cls=VectorStoreIndex,
)
Now we create our top-level agent. This will use the tool retriever that we just created.
from llama_index.agent.openai import OpenAIAgent
top_agent = OpenAIAgent.from_tools(
tool_retriever=obj_index.as_retriever(similarity_top_k=3),
system_prompt=""" \
You are an agent designed to answer queries about a set of given cities.
Please always use the tools provided to answer a question. Do not rely on prior knowledge.\
""",
verbose=True,
)
Testing our agent
Let’s now run some queries and see how the results look:
# should use Boston agent -> vector tool
response = top_agent.query("Tell me about the arts and culture in Boston")
=== Calling Function ===
Calling function: tool_Boston with args: {
"input": "arts and culture"
}
=== Calling Function ===
Calling function: vector_tool with args: {
"input": "arts and culture"
}
Got output: Boston is known for its vibrant arts and culture scene. The city is home to a number of performing arts organizations, including the Boston Ballet, Boston Lyric Opera Company, Opera Boston, Boston Baroque, and the Handel and Haydn Society. There are also several theaters in or near the Theater District, such as the Cutler Majestic Theatre, Citi Performing Arts Center, the Colonial Theater, and the Orpheum Theatre. Boston is a center for contemporary classical music, with groups like the Boston Modern Orchestra Project and Boston Musica Viva. The city also hosts major annual events, such as First Night, the Boston Early Music Festival, and the Boston Arts Festival. In addition, Boston has several art museums and galleries, including the Museum of Fine Arts, the Isabella Stewart Gardner Museum, and the Institute of Contemporary Art.
========================
Got output: Boston is renowned for its vibrant arts and culture scene. It is home to numerous performing arts organizations, including the Boston Ballet, Boston Lyric Opera Company, Opera Boston, Boston Baroque, and the Handel and Haydn Society. The city's Theater District houses several theaters, such as the Cutler Majestic Theatre, Citi Performing Arts Center, the Colonial Theater, and the Orpheum Theatre.
Boston is also a hub for contemporary classical music, with groups like the Boston Modern Orchestra Project and Boston Musica Viva. The city hosts major annual events, such as First Night, the Boston Early Music Festival, and the Boston Arts Festival, which contribute to its cultural richness.
In terms of visual arts, Boston boasts several art museums and galleries. The Museum of Fine Arts, the Isabella Stewart Gardner Museum, and the Institute of Contemporary Art are among the most notable. These institutions offer a wide range of art collections, from ancient to contemporary, attracting art enthusiasts from around the world.
========================
print(response)
Boston has a rich arts and culture scene, with a variety of performing arts organizations and venues. The city is home to renowned institutions such as the Boston Ballet, Boston Lyric Opera Company, Opera Boston, Boston Baroque, and the Handel and Haydn Society. The Theater District in Boston is a hub for theatrical performances, with theaters like the Cutler Majestic Theatre, Citi Performing Arts Center, Colonial Theater, and Orpheum Theatre.
In addition to performing arts, Boston also has a thriving contemporary classical music scene, with groups like the Boston Modern Orchestra Project and Boston Musica Viva. The city hosts several annual events that celebrate the arts, including First Night, the Boston Early Music Festival, and the Boston Arts Festival.
Boston is also known for its visual arts scene, with a number of art museums and galleries. The Museum of Fine Arts, the Isabella Stewart Gardner Museum, and the Institute of Contemporary Art are among the notable institutions in the city. These museums offer a diverse range of art collections, spanning from ancient to contemporary art, and attract art enthusiasts from around the world.
We can see based on the response that our parent agent calls the correct agent, which is the Boston agent. It then uses the Boston agent to query and get the correct information.
The parent agent chooses the Boston agent and then calls it here:
=== Calling Function ===
Calling function: tool_Boston with args: {
"input": "arts and culture"
}
The Boston agent then is called here:
=== Calling Function ===
Calling function: vector_tool with args: {
"input": "arts and culture"
}
Summary
These are a few exmaples of using LlamaIndex for creating agents. This is a good overview of LlamaIndex, what it does, and how it fits into the LLMOps pipeline and workflow.