
What I’m reading today (2025-09-26)
What I’m reading today (2025-09-26)
A brief compilation of things I’m reading and looking at today. Includes link to resource, as well as (1) key insight in plain English, (2) my brief thoughts as well as where this plugs into my work today, and (3) follow-up action (if any). Recording my readings like this helps keep me accountable to understanding what I’m reading, while also keeping it light and sustainable.
1: LLM-as-a-Judge (Comet)
- Source: https://www.comet.com/site/blog/llm-as-a-judge/
- Key insight: brief overview of how LLM-as-a-Judge works. Mostly stuff that I already knew at some level, but haven’t gotten a chance to really take a crack at.
- Thoughts and follow-up: I’m at a point where I have some more bandwidth and leeway for some new projects in my research, plus I think that our research could do well to adopt AI and LLM reproducibility best practices, so I’ll find a way to introduce eval scaffolding and LLM-as-a-Judge to what I’m working on. In the context of what I do, I think evals scaffolding will probably serve as something like what “developer experience” roles do in industry, meaning it greatly amplifies the productivity and experience of devs. In lieu of devs, I’m thinking here of academics.
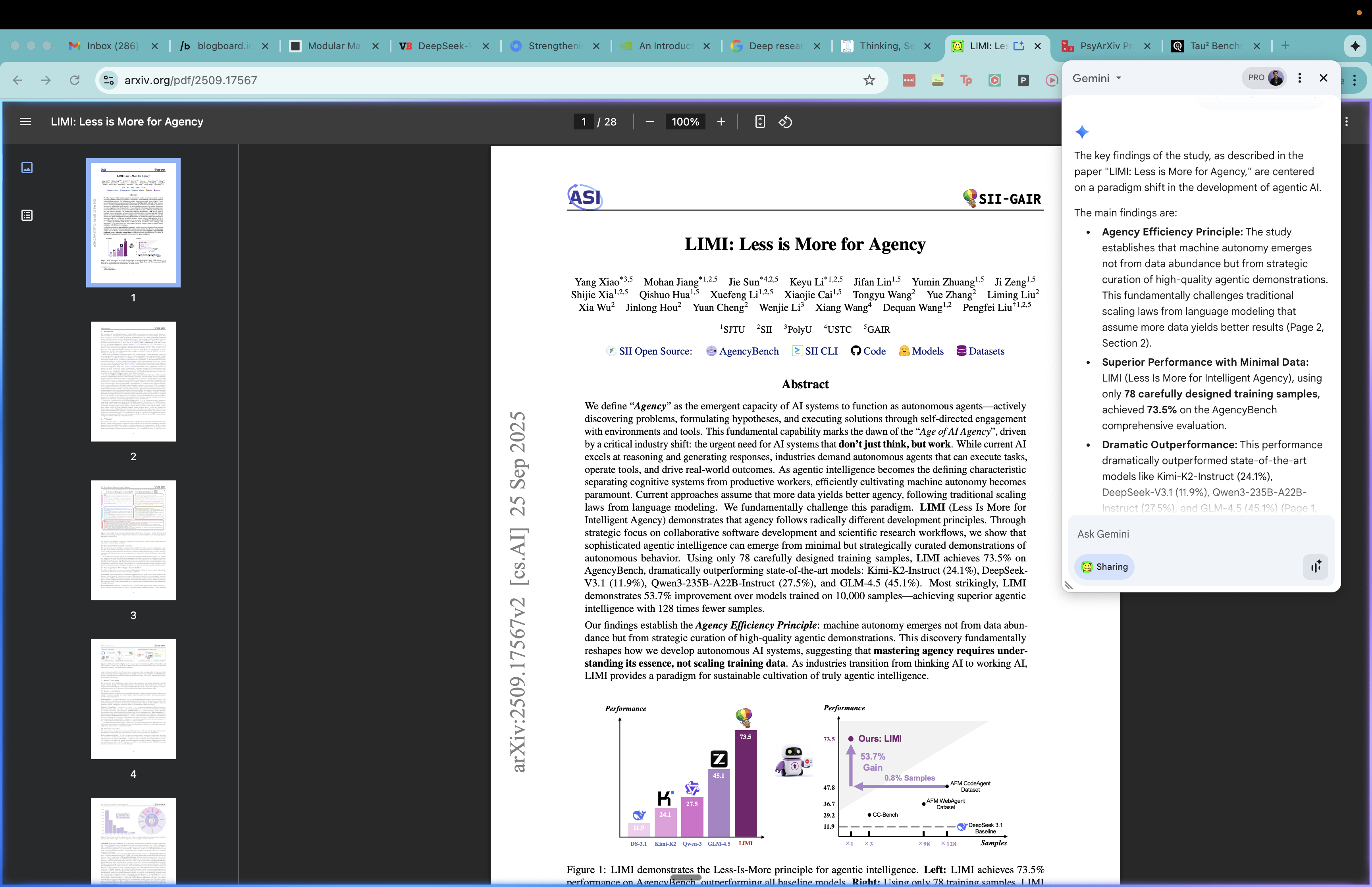
2: LIMI: Less is More for Agency
- Source: https://arxiv.org/pdf/2509.17567
- Key insight: Curating datasets for AI agents is more sensitive to data quality than data quantity. Teams are better off curating low sample sizes of very high quality data than large sample sizes of mediocre data.
- Thoughts and follow-up: I’ve done some consulting work with frontier labs and I’ve seen the rigor that goes into the data curation and preparation pipeline, especially for fine-tuning AI agents. None of the key findings here particularly surprise me, though the magnitude of the effects were still impressive. Even if you, for example, scrape Github PRs as part of SWE-bench, just because code is in a PR doesn’t mean it’s high-quality. Garbage in, garbage out. This paper reads like an extension of that line of work.
Bonus: I started using the Gemini browser extension, and it’s a really great general tool that I can use to quickly and easily understand what I’m seeing on the screen. Here, I have a really quick way to be able to clarify my understanding and ask questions about the paper I’m reading. This really helps improves my understanding!
3. How a Prompt Rewrite Boosted GPT-5-mini by 22%
- Source: https://quesma.com/blog/tau2-benchmark-improving-results-smaller-models/
- Key insight: The team wanted to see if they could improve the performance of a small model (GPT 5 mini) by using Claude to rewrite the prompt, and turns out it improves the performance on a particular benchmark by 20%.
- Thoughts and follow-up: Turns out it really is as easy as rewriting a prompt, huh? Sometimes people underestimate the power of copying and pasting your prompt into Claude and asking it to write a better version for you. One could argue that a sufficiently capable AI model should be invariant to prompt quality, as long as the task is well-defined, but it turns out that we’re not there yet with this iteration of models. The PR of the prompt rewrite is interesting and I might have to update my own AI prompts accordingly. I like the checklist-based approach for this.