
Experiments with LLM classification for political content (Part VIII)
Using LLMs to classify if social media posts are political or not (Part VIII).
I’m working on a project that involves gathering social media posts from Bluesky and analyzing them. Part of that project requires knowing which posts are about political or social topics, and if so, what political side they support. Current ML classifiers don’t work that well out of the box, so I’m trying to create our own classification scheme using LLMs. I’m trying to use LLMs in order to classify Bluesky posts as either having political content or not, and if so, the political ideology, and I’ve found that LLMs work quite well for this task. I’ve used Llama3-8b and Llama3-70b via Groq so far, but are also open to experimenting with other open-source models as well (I have the on-prem infrastructure to host our own models, which is much cheaper at scale).
I’ve confirmed previously that LLMs are promising for our classification task. I also cleaned up the code to have a more robust ETL pipeline. Now, I want to move everything over to the Kellogg Linux Cluster (KLC), which will serve as a way for us to get the at-scale computing needs required for the project.
Specifically, I’ll do the following
- Set up KLC access
- Create a cron job for running daily pipeline syncs of Bluesky posts
Set up KLC access
First, I need to start by setting up KLC access. Luckily, this process is pretty well-documented, so what I’m doing is based primarily on this resource. I also need to do this while on the university VPN, with instructions here.
After I’ve set up VPN access, I can ssh into the cluster:
ssh <netid>@quest.northwestern.edu
Once this was set up, I’m directed to my personal storage on the cluster. Now I need to find my project’s folder, since the docs talk about how the space allocated to each user’s personal folder is quite small (a few GBs) but the space allocated to a project folder can be quite large (in our case, our project was allocated 1TB). This document has details on how to do this process (as well as how to request project allocation if necessary).
Now I’ll load conda. I’ll follow these docs as well as play around with using mamba for loading conda, since mamba is, according to blogs like this, more efficient at package management than conda, but lets me use both conda and pip. So far, this is how that looks:

Now I need to set up Git. This wasn’t too bad, here are resources on how to do this on KLC. I found authentication to be easiest once I could use the Github CLI, and installing it was straightforward via conda. I verified that a file that I wrote and uploaded on the cluster was successfully pushed to my repo.
I also set up SSH keys so that I don’t have to keep passing in my password each time. That was actually pretty straightforward, and I was surprised to find that ChatGPT nailed the instructions.
I then set up remote SSH tunneling with VSCode so that I could access the cluster via VSCode. I’ll still likely do most development locally, but this makes it much easier to do any changes that are easier to do while accessing the remote cluster (such as, for example, accessing data stored on KLC).
Create a cron job for running daily syncs of Bluesky posts
Now that we’ve set up access, we can use KLC to do things that require more compute and memory.
Setting up the data pipeline
This basic interface that I’ll be using for running the data pipeline, build with typer for a nicer CLI interface.
"""Pipeline for getting posts from Bluesky.
Can either fetch raw posts from the firehose or from the "Most Liked" feed.
Run via `typer`: https://pypi.org/project/typer/
Example usage:
>>> python main.py --sync-type firehose
"""
import sys
import typer
from typing_extensions import Annotated
from most_liked import get_posts as get_most_liked_posts
from firehose import get_posts as get_firehose_posts
from enum import Enum
class SyncType(str, Enum):
firehose = "firehose"
most_liked = "most_liked"
def main(
sync_type: Annotated[
SyncType, typer.Option(help="Type of sync")
]
):
sync_type = sync_type.value
if sync_type == "firehose":
get_firehose_posts()
elif sync_type == "most_liked":
get_most_liked_posts()
else:
print("Invalid sync type.")
sys.exit(1)
if __name__ == "__main__":
typer.run(main)
There are two types of posts that we want to sync:
- The firehose posts: these are posts from the Bluesky firehose, which constantly updates whenever a new post is written on Bluesky. We’ll be able to get all the posts from Bluesky as they’re written in real time.
- The most liked posts: these are the posts that have been the most liked in the past 24 hours. According to the docs, the “catch-up” feed (the most-liked posts the past 24 hours) consists of the top 1,000 posts with the most likes in the past 24 hours. This feed appears to be consistently refreshed to have the latest most liked posts in the 24 hour period starting with whenever the feed is fetched, ensuring that if we collect posts 24 hours apart, we’ll have completely different posts in our feed.
What I want to do is:
- For the firehose posts, pick X hours out of the day (maybe something like 4?) and run the firehose. While the firehose is running, we’ll save all the new posts that are being written to Bluesky, in real time.
- For the most liked posts, fetch the latest posts from the most liked posts in the past 24 hours.
I’ll store the firehose posts in a SQLite database for now and then store the most liked posts in a remote MongoDB database. Ideally I’d store everything in a NoSQL database, and eventually I’ll set up a MongoDB server on KLC, but for now I’ll work with what I have.
How much data should we expect to sync per day?
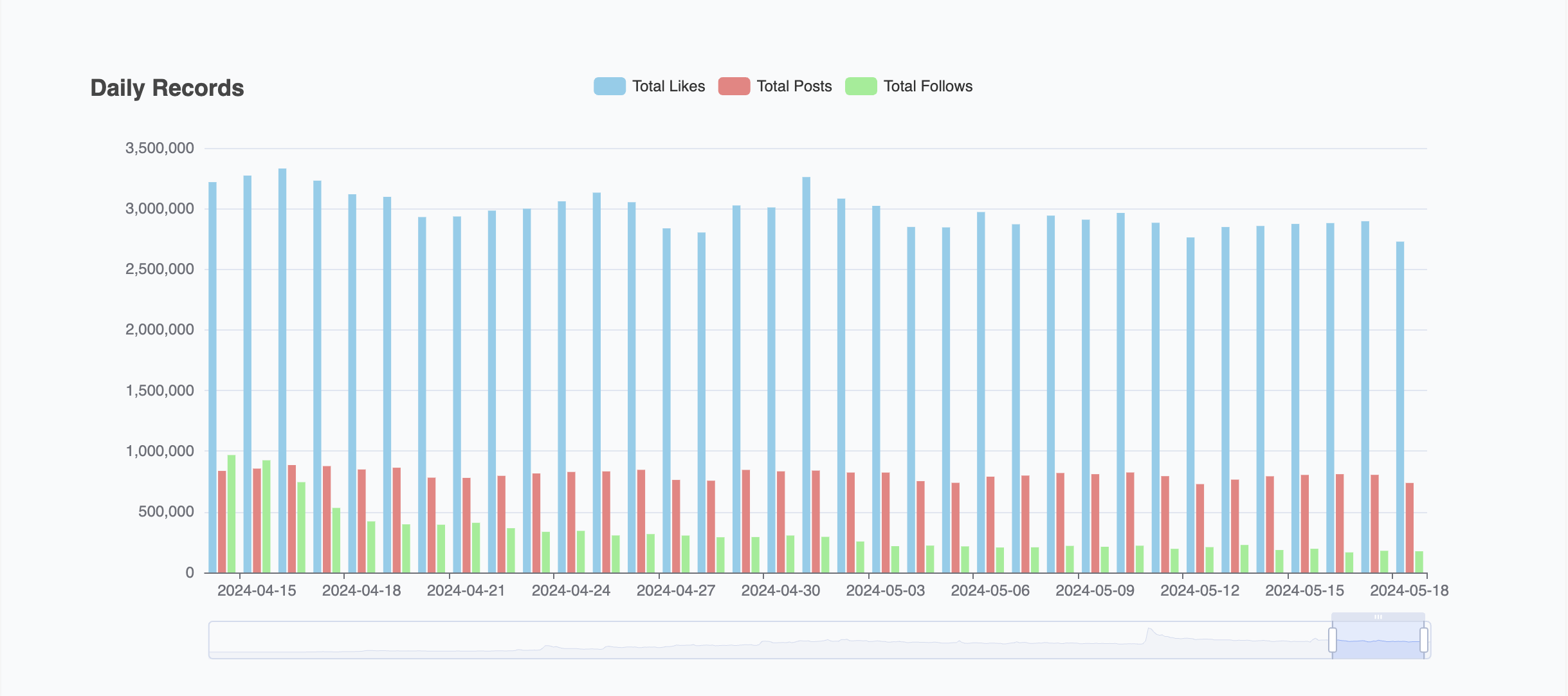
For the most liked posts, we know that we can expect up to 1,000 posts per day. For the firehose posts, this dashboard, built by one of the core Bluesky developers, gives us baseline rates, in real time, of activity on Bluesky.
According to the following graphic from that dashboard, it looks like the past month, as per the writing of this document, has averaged ~800,000 posts per day.
Setting up the sync for the firehose posts
We already have a service that will connect to the Bluesky firehose and run until some end condition is met.
We can set some artificial number of posts for the firehose to sync before it stops, or have it run for a certain amount of time. I’ll do the former, so we can have consistent guarantees on the number of posts that we’re fetching from the firehose.
From past experiments, about 20% of posts end up being English-language posts (primarily due to language but also due to, for example, the posts being marked as spam or as NSFW). If we want to collect, say, 20,000 English posts per day and if we assume that only 10% of our posts will pass filtering, we’d need at least 100,000 posts synced per day. If we know that each day there’s expected to be around 800,000 posts, we can expect to easily get 100,000 posts per day. Let’s be safe and aim to get 150,000 posts instead, to get more data.
The firehose also contains other events, such as post deletes and post likes. I’ve found through testing that about 20% of firehose events are new posts. So, if we want to get 150,000 posts per day, we will need to process 750,000 events.
Our firehose code looks like this:
"""Firehose stream service.
Based on https://github.com/MarshalX/bluesky-feed-generator/blob/main/server/data_stream.py
""" # noqa
import sys
from atproto import (
AtUri, CAR, firehose_models, FirehoseSubscribeReposClient, models,
parse_subscribe_repos_message
)
from atproto.exceptions import FirehoseError
from lib.helper import ThreadSafeCounter
from services.sync.stream.database import SubscriptionState
from services.sync.stream.helper import get_num_posts
# 150,000 posts expected.
stream_limit = 750000
# how often to update the post counts
cursor_update_frequency = 500
def _get_ops_by_type(commit: models.ComAtprotoSyncSubscribeRepos.Commit) -> dict: # noqa
operation_by_type = {
'posts': {'created': [], 'deleted': []},
# NOTE: is it possible to track reposts?
'reposts': {'created': [], 'deleted': []},
'likes': {'created': [], 'deleted': []},
'follows': {'created': [], 'deleted': []},
}
car = CAR.from_bytes(commit.blocks)
for op in commit.ops:
uri = AtUri.from_str(f'at://{commit.repo}/{op.path}')
if op.action == 'update':
# not supported yet
continue
if op.action == 'create':
if not op.cid:
continue
create_info = {'uri': str(uri), 'cid': str(
op.cid), 'author': commit.repo}
record_raw_data = car.blocks.get(op.cid)
if not record_raw_data:
continue
record = models.get_or_create(record_raw_data, strict=False)
if (
uri.collection == models.ids.AppBskyFeedLike
and models.is_record_type(record, models.AppBskyFeedLike)
):
operation_by_type['likes']['created'].append(
{'record': record, **create_info})
elif (
uri.collection == models.ids.AppBskyFeedPost
and models.is_record_type(record, models.AppBskyFeedPost)
):
operation_by_type['posts']['created'].append(
{'record': record, **create_info})
elif (
uri.collection == models.ids.AppBskyGraphFollow
and models.is_record_type(record, models.AppBskyGraphFollow)
):
operation_by_type['follows']['created'].append(
{'record': record, **create_info})
if op.action == 'delete':
if uri.collection == models.ids.AppBskyFeedLike:
operation_by_type['likes']['deleted'].append({'uri': str(uri)})
if uri.collection == models.ids.AppBskyFeedPost:
operation_by_type['posts']['deleted'].append({'uri': str(uri)})
if uri.collection == models.ids.AppBskyGraphFollow:
operation_by_type['follows']['deleted'].append(
{'uri': str(uri)})
return operation_by_type
def run(name, operations_callback, stream_stop_event=None):
while stream_stop_event is None or not stream_stop_event.is_set():
try:
_run(name, operations_callback, stream_stop_event)
except FirehoseError as e:
# here we can handle different errors to reconnect to firehose
raise e
def _run(name, operations_callback, stream_stop_event=None): # noqa: C901
state = SubscriptionState.select(SubscriptionState.service == name).first()
params = None
if state:
params = models.ComAtprotoSyncSubscribeRepos.Params(
cursor=state.cursor)
client = FirehoseSubscribeReposClient(params)
if not state:
SubscriptionState.create(service=name, cursor=0)
counter = ThreadSafeCounter()
def on_message_handler(message: firehose_models.MessageFrame) -> None:
# stop on next message if requested
if stream_stop_event and stream_stop_event.is_set():
client.stop()
return
# possible types of messages: https://github.com/bluesky-social/atproto/blob/main/packages/api/src/client/lexicons.ts#L3298 # noqa
if message.type == "#identity":
return
commit = parse_subscribe_repos_message(message)
if not isinstance(commit, models.ComAtprotoSyncSubscribeRepos.Commit):
return
# update stored state
if commit.seq % cursor_update_frequency == 0:
print(f'Updated cursor for {name} to {commit.seq}')
client.update_params(
models.ComAtprotoSyncSubscribeRepos.Params(cursor=commit.seq))
SubscriptionState.update(cursor=commit.seq).where(
SubscriptionState.service == name).execute()
if not commit.blocks:
return
has_written_data = operations_callback(_get_ops_by_type(commit))
# we assume that the write to DB has succeeded, though we may want to
# validate this check (i.e., has_written_data is always True, but
# we may want to see if this is actually the case.)
if has_written_data:
counter.increment()
counter_value = counter.get_value()
if counter_value % cursor_update_frequency == 0:
print(f"Counter: {counter_value}")
if counter.get_value() > stream_limit:
total_posts_in_db: int = get_num_posts()
print(f"Counter value {counter_value} > stream limit: {stream_limit}. Total posts in DB: {total_posts_in_db}. Exiting...") # noqa
sys.exit(0)
client.start(on_message_handler)
We can kick this off from a centralized app:
import sys
import signal
import threading
import time
from flask import Flask
from services.sync.stream import firehose
from services.sync.stream.data_filter import operations_callback
app = Flask(__name__)
firehose_name = "firehose_stream"
def start_app():
start_time = time.time()
stream_stop_event = threading.Event()
stream_args = (firehose_name, operations_callback, stream_stop_event)
stream_thread = threading.Thread(target=firehose.run, args=stream_args)
print('Starting data stream...')
# something like 3:49pm UTC
start_time_str = time.strftime('%Y-%m-%d %H:%M:%S', time.gmtime(start_time))
print(f"Start time: {start_time_str}")
stream_thread.start()
def sigint_handler(*_):
print('Stopping data stream...')
stream_stop_event.set()
stream_thread.join() # wait for thread to finish
end_time = time.time()
end_time_str = time.strftime('%Y-%m-%d %H:%M:%S', time.gmtime(end_time))
total_minutes = round((end_time - start_time) / 60, 1)
print(f"End time: {end_time_str}")
print(f"Total runtime: {total_minutes} minutes")
sys.exit(0)
signal.signal(signal.SIGINT, sigint_handler)
if __name__ == "__main__":
start_app()
We then simply call this from our pipeline:
from services.sync.stream.app import start_app
def get_posts() -> None:
print("Getting posts from the firehose.")
start_app()
We can test this and verify that this works.
(bluesky-research) ➜ sync_post_records git:(main) ✗ python main.py --sync-type firehose
HTTP Request: POST https://bsky.social/xrpc/com.atproto.server.createSession "HTTP/1.1 200 OK"
HTTP Request: GET https://bsky.social/xrpc/app.bsky.actor.getProfile?actor=mindtechnologylab.bsky.social "HTTP/1.1 200 OK"
Getting posts from the firehose.
Starting data stream...
Start time: 2024-05-21 11:47:37
Updated cursor for firehose_stream to 504570500
Counter: 500
Updated cursor for firehose_stream to 504571000
Counter: 1000
Setting up the sync for the most liked posts
For the most liked posts, we just have to fetch posts from the “Catch-Up” feed, which will show the most liked feeds on Bluesky in the past 24 hours. We can run this at a point in time and collect all the posts in the feed. I detailed how the code to sync posts from MongoDB in this post, but I still need to connect it to the data pipeline.
This is the existing code that I already have for syncing the most liked posts:
def get_and_transform_latest_most_liked_posts(
feeds: list[str] = ["today", "week"]
) -> list[TransformedFeedViewPostModel]:
"""Get the latest batch of most liked posts and transform them."""
res: list[TransformedFeedViewPostModel] = []
for feed in feeds:
feed_url = feed_to_info_map[feed]["url"]
enrichment_data = {
"source_feed": feed, "feed_url": feed_url
}
print(f"Getting most liked posts from {feed} feed with URL={feed_url}")
posts: list[FeedViewPost] = get_posts_from_custom_feed_url(
feed_url=feed_url, limit=None
)
transformed_posts: list[TransformedFeedViewPostModel] = (
transform_feedview_posts(
posts=posts, enrichment_data=enrichment_data
)
)
res.extend(transformed_posts)
print(f"Finished processing {len(posts)} posts from {feed} feed")
return res
def main(
use_latest_local: bool = False,
store_local: bool = True,
store_remote: bool = True,
bulk_write_remote: bool = True,
feeds: list[str] = ["today", "week"]
) -> None:
if use_latest_local:
post_dicts: list[dict] = filter_most_recent_local_sync()
else:
posts: list[TransformedFeedViewPostModel] = (
get_and_transform_latest_most_liked_posts(feeds=feeds)
)
filtered_posts: list[TransformedFeedViewPostModel] = filter_posts(posts=posts) # noqa
post_dicts = [post.dict() for post in filtered_posts]
export_posts(
posts=post_dicts, store_local=store_local,
store_remote=store_remote, bulk_write_remote=bulk_write_remote
)
We can now call this from our pipeline:
from services.sync.most_liked_posts.helper import main as get_most_liked_posts
def get_posts() -> None:
print("Getting posts from the most liked feed.")
args = {
"use_latest_local": False,
"store_local": True,
"store_remote": True,
"bulk_write_remote": True,
"feeds": ["today"]
}
get_most_liked_posts(**args)
We can test this and verify that it works:
(bluesky-research) ➜ sync_post_records git:(main) ✗ python main.py --sync-type most_liked
HTTP Request: POST https://bsky.social/xrpc/com.atproto.server.createSession "HTTP/1.1 200 OK"
HTTP Request: GET https://bsky.social/xrpc/app.bsky.actor.getProfile?actor=mindtechnologylab.bsky.social "HTTP/1.1 200 OK"
Warning : `load_model` does not return WordVectorModel or SupervisedModel any more, but a `FastText` object which is very similar.
Getting posts from the most liked feed.
Getting most liked posts from today feed with URL=https://bsky.app/profile/did:plc:tenurhgjptubkk5zf5qhi3og/feed/catch-up
Fetching 100 results, out of total max of 999999...
HTTP Request: GET https://bsky.social/xrpc/app.bsky.feed.getFeed?feed=at%3A%2F%2Fdid%3Aplc%3Atenurhgjptubkk5zf5qhi3og%2Fapp.bsky.feed.generator%2Fcatch-up&limit=100 "HTTP/1.1 200 OK"
Fetching 100 results, out of total max of 999999...
HTTP Request: GET https://bsky.social/xrpc/app.bsky.feed.getFeed?feed=at%3A%2F%2Fdid%3Aplc%3Atenurhgjptubkk5zf5qhi3og%2Fapp.bsky.feed.generator%2Fcatch-up&cursor=_Yhh1Oge6nw1Uo1w_Lv1QaoieQ2ZaWbTJlC7PePhnU8%2Bat%3A%2F%2Fdid%3Aplc%3Apum3nk6m6xqwqw5e7v5wcbgu%2Fapp.bsky.feed.post%2F3kswfmvierk2w&limit=100 "HTTP/1.1 200 OK"
Fetching 100 results, out of total max of 999999...
HTTP Request: GET https://bsky.social/xrpc/app.bsky.feed.getFeed?feed=at%3A%2F%2Fdid%3Aplc%3Atenurhgjptubkk5zf5qhi3og%2Fapp.bsky.feed.generator%2Fcatch-up&cursor=_Yhh1Oge6nw1Uo1w_Lv1QaoieQ2ZaWbTJlC7PePhnU8%2Bat%3A%2F%2Fdid%3Aplc%3Agfn6cotedq5dktlkanw4c47o%2Fapp.bsky.feed.post%2F3ksxpcjnx4q23&limit=100 "HTTP/1.1 200 OK"
Fetching 100 results, out of total max of 999999...
HTTP Request: GET https://bsky.social/xrpc/app.bsky.feed.getFeed?feed=at%3A%2F%2Fdid%3Aplc%3Atenurhgjptubkk5zf5qhi3og%2Fapp.bsky.feed.generator%2Fcatch-up&cursor=_Yhh1Oge6nw1Uo1w_Lv1QaoieQ2ZaWbTJlC7PePhnU8%2Bat%3A%2F%2Fdid%3Aplc%3Ahwmmdl5nok26w3zhmg2d3fvt%2Fapp.bsky.feed.post%2F3ksxm53nhat26&limit=100 "HTTP/1.1 200 OK"
Fetching 100 results, out of total max of 999999...
HTTP Request: GET https://bsky.social/xrpc/app.bsky.feed.getFeed?feed=at%3A%2F%2Fdid%3Aplc%3Atenurhgjptubkk5zf5qhi3og%2Fapp.bsky.feed.generator%2Fcatch-up&cursor=_Yhh1Oge6nw1Uo1w_Lv1QaoieQ2ZaWbTJlC7PePhnU8%2Bat%3A%2F%2Fdid%3Aplc%3Auraielgolztbeqrrv5c7qbce%2Fapp.bsky.feed.post%2F3kswwyttag22o&limit=100 "HTTP/1.1 200 OK"
Fetching 100 results, out of total max of 999999...
HTTP Request: GET https://bsky.social/xrpc/app.bsky.feed.getFeed?feed=at%3A%2F%2Fdid%3Aplc%3Atenurhgjptubkk5zf5qhi3og%2Fapp.bsky.feed.generator%2Fcatch-up&cursor=_Yhh1Oge6nw1Uo1w_Lv1QaoieQ2ZaWbTJlC7PePhnU8%2Bat%3A%2F%2Fdid%3Aplc%3Aqjpmddmvbju7udpvanfmzbnq%2Fapp.bsky.feed.post%2F3kswdwil6gz2c&limit=100 "HTTP/1.1 200 OK"
Fetching 100 results, out of total max of 999999...
HTTP Request: GET https://bsky.social/xrpc/app.bsky.feed.getFeed?feed=at%3A%2F%2Fdid%3Aplc%3Atenurhgjptubkk5zf5qhi3og%2Fapp.bsky.feed.generator%2Fcatch-up&cursor=_Yhh1Oge6nw1Uo1w_Lv1QaoieQ2ZaWbTJlC7PePhnU8%2Bat%3A%2F%2Fdid%3Aplc%3Awbcudwitx6da673hkkyjgyvt%2Fapp.bsky.feed.post%2F3kswbrwzxv42b&limit=100 "HTTP/1.1 200 OK"
Fetching 100 results, out of total max of 999999...
HTTP Request: GET https://bsky.social/xrpc/app.bsky.feed.getFeed?feed=at%3A%2F%2Fdid%3Aplc%3Atenurhgjptubkk5zf5qhi3og%2Fapp.bsky.feed.generator%2Fcatch-up&cursor=_Yhh1Oge6nw1Uo1w_Lv1QaoieQ2ZaWbTJlC7PePhnU8%2Bat%3A%2F%2Fdid%3Aplc%3Aemt3p4o44z7joo4cdxfgkdb6%2Fapp.bsky.feed.post%2F3kswkdb7vld26&limit=100 "HTTP/1.1 200 OK"
Fetching 100 results, out of total max of 999999...
HTTP Request: GET https://bsky.social/xrpc/app.bsky.feed.getFeed?feed=at%3A%2F%2Fdid%3Aplc%3Atenurhgjptubkk5zf5qhi3og%2Fapp.bsky.feed.generator%2Fcatch-up&cursor=_Yhh1Oge6nw1Uo1w_Lv1QaoieQ2ZaWbTJlC7PePhnU8%2Bat%3A%2F%2Fdid%3Aplc%3Apzvko3dvcjbysqakwci3t3gf%2Fapp.bsky.feed.post%2F3ksxuciznty2q&limit=100 "HTTP/1.1 200 OK"
Fetching 100 results, out of total max of 999999...
HTTP Request: GET https://bsky.social/xrpc/app.bsky.feed.getFeed?feed=at%3A%2F%2Fdid%3Aplc%3Atenurhgjptubkk5zf5qhi3og%2Fapp.bsky.feed.generator%2Fcatch-up&cursor=_Yhh1Oge6nw1Uo1w_Lv1QaoieQ2ZaWbTJlC7PePhnU8%2Bat%3A%2F%2Fdid%3Aplc%3A6sdn2o7q6tpzfwkcqdinx5sw%2Fapp.bsky.feed.post%2F3kswirtraid2g&limit=100 "HTTP/1.1 200 OK"
Fetching 100 results, out of total max of 999999...
HTTP Request: GET https://bsky.social/xrpc/app.bsky.feed.getFeed?feed=at%3A%2F%2Fdid%3Aplc%3Atenurhgjptubkk5zf5qhi3og%2Fapp.bsky.feed.generator%2Fcatch-up&cursor=_Yhh1Oge6nw1Uo1w_Lv1QaoieQ2ZaWbTJlC7PePhnU8%2Bat%3A%2F%2Fdid%3Aplc%3A44athciecdhwxyqysbeurkbj%2Fapp.bsky.feed.post%2F3kswynlowh22n&limit=100 "HTTP/1.1 200 OK"
Finished processing 999 posts from today feed
FYI: for this particular sync, I found that 789 out of 999 posts (79%) of posts are English. This is a higher rate than the 20% or so of our firehose posts that are written in English.
Setting up the cron job
When to kick off the cron job
Since we want our posts to be primarily English-language and revolving around US news and events, we’ll want to run the code during times in which US-based users are likely to be active. We’ll kick this off around 6pm Eastern, arbitrarily assuming that that’s when people start to be more active online. For simplicity’s sake, we’ll just run this with a cron job (no need to use some more high-powered orchestration tooling).
Implementing the cron job via bash script
The following is a bash script that, according to ChatGPT, will set up the cron job for running this code at 4pm Central every day.
#!/bin/bash
# This bash script will create a cron job that runs the sync pipeline via main.py everyday at 5pm Eastern Time (currently UTC-5)/4pm Central.
# It will execute two commands:
# - python main.py --sync-type firehose
# - python main.py --sync-type most_liked
# Get the current directory
DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
# load conda env
CONDA_PATH="/hpc/software/mamba/23.1.0/etc/profile.d/conda.sh"
# set pythonpath
PYTHONPATH="/projects/p32375/bluesky-research/:$PYTHONPATH"
# 4pm Central
CRON_EXPRESSION="0 16 * * *"
# Define the cron job command
CRON_JOB_FIREHOSE="$CRON_EXPRESSION source $CONDA_PATH && conda activate bluesky_research && export PYTHONPATH=$PYTHONPATH && cd $DIR && python main.py --sync-type firehose >> /projects/p32375/bluesky-research/lib/log/logfile.log"
CRON_JOB_MOST_LIKED="$CRON_EXPRESSION source $CONDA_PATH && conda activate bluesky_research && export PYTHONPATH=$PYTHONPATH && cd $DIR && python main.py --sync-type most_liked >> /projects/p32375/bluesky-research/lib/log/logfile.log"
# Add the cron job to the current user's crontab
(crontab -l 2>/dev/null; echo "$CRON_JOB_FIREHOSE") | crontab -
(crontab -l 2>/dev/null; echo "$CRON_JOB_MOST_LIKED") | crontab -
#(crontab -l 2>/dev/null; echo "$TESTCRON") | crontab -
echo "Cron jobs created to run sync pipelines everyday at 4pm Central Time."
Running the cron job on KLC
Let’s now pull the latest commits into KLC and then run the bash script to schedule the cron job.
Then, let’s give our user the permissions required to run the file:
chmod +x create_cron_job.sh
./create_cron_job.sh
We can now see that the cron job is scheduled:

Let’s also now set up some basic logging. First, here’s a setup for creating a logger and adding configs.
"""Creates wrapper logger class."""
import logging
from logging.handlers import RotatingFileHandler
import os
from typing import Any, Dict
log_directory = os.path.dirname(os.path.abspath(__file__))
os.makedirs(log_directory, exist_ok=True)
log_filename = os.path.join(log_directory, "logfile.log")
# mypy: ignore-errors
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s %(levelname)s [%(filename)s]: %(message)s",
handlers=[
logging.StreamHandler(),
# Rotating log file, 1MB max size, keeping 5 backups
RotatingFileHandler(log_filename, maxBytes=1024 * 1024, backupCount=5),
],
)
# mypy: ignore-errors
class Logger(logging.Logger):
def __init__(self, name: str, level: int = logging.INFO) -> None:
super().__init__(name, level)
def log(self, message: str, **kwargs: Dict[str, Any]) -> None:
"""Convenience method to log a message with some extra data."""
self.info(message, extra=kwargs)
We now add this logger to all of the relevant places:
First, when fetching posts from the firehose.
from lib.log.logger import Logger
from services.sync.stream.app import start_app
logger = Logger()
def get_posts() -> None:
logger.info("Getting posts from the firehose.")
try:
start_app()
logger.info("Successfully fetched posts from the firehose.")
except Exception as e:
logger.error(f"Error getting posts from the firehose: {e}")
raise
Then, posts from the most liked feed.
from lib.log.logger import Logger
from services.sync.most_liked_posts.helper import main as get_most_liked_posts
logger = Logger()
def get_posts() -> None:
logger.info("Getting posts from the most liked feed.")
try:
args = {
"use_latest_local": False,
"store_local": True,
"store_remote": True,
"bulk_write_remote": True,
"feeds": ["today"]
}
get_most_liked_posts(**args)
logger.info("Successfully got posts from the most liked feed.")
except Exception as e:
logger.error(f"Error getting posts from the most liked feed: {e}")
raise
Finally, the centralized pipeline.
"""Pipeline for getting posts from Bluesky.
Can either fetch raw posts from the firehose or from the "Most Liked" feed.
Run via `typer`: https://pypi.org/project/typer/
Example usage:
>>> python main.py --sync-type firehose
"""
import sys
import typer
from typing_extensions import Annotated
from firehose import get_posts as get_firehose_posts
from lib.log.logger import Logger
from most_liked import get_posts as get_most_liked_posts
from enum import Enum
logger = Logger()
class SyncType(str, Enum):
firehose = "firehose"
most_liked = "most_liked"
def main(
sync_type: Annotated[
SyncType, typer.Option(help="Type of sync")
]
):
try:
logger.fino(f"Starting sync with type: {sync_type}")
if sync_type == "firehose":
get_firehose_posts()
elif sync_type == "most_liked":
get_most_liked_posts()
else:
print("Invalid sync type.")
logger.error("Invalid sync type provided.")
sys.exit(1)
logger.info(f"Completed sync with type: {sync_type}")
except Exception as e:
logger.error(f"Error in sync pipeline: {e}")
sys.exit(1)
if __name__ == "__main__":
typer.run(main)
Later, we’ll look at the log outputs from the pipeline job as well as the cron job outputs.
We can take a look at the logs, from testing, to see what this will look like:
Summary and next steps
This is an overview of how I set up access to a remote computing cluster, migrated my code to said cluster, and then set up my data pipeline to run Some other remaining TODO items are:
- Updating and refactoring the LLM pipeline to label the posts efficiently at scale.
- Running LLM inference on KLC with Llama3 (both small and large models).
- Comparing how our model perform with other LLMs (e.g., Mixtral)?
- Experimenting with optimizing the prompt (e.g, with dspy)?
I’d also like to revisit some of the points related to improving how to add context about current events:
- For determining when to get context for a post, investigate various strategies such as:
- Keyword matching: see if a keyword (e.g., a name of an event) comes up. Need to figure out keywords that describe topics that are in the news (this is easiest if it is the name of a notable event, place, person, piece of legislature, etc.) and then we can easily pattern match that against posts that have that keyword.
- Posts that the LLM knows is political but isn’t sure what the political ideology is.
- Determine how to format the context that’s given to the LLM prompt.
- An interesting frame could be first asking the LLM to distill the sentiments and thoughts of each political party about a certain topic, based on the articles that we have for each topic, and then passing this distilled summary to the LLM itself.
- Only insert into the vector store if it doesn’t already exist there.
- At some point, add a maximum distance measure so we get only relevant articles (will take some experimentation in order to see what a good distance is).