
Experiments with LLM classification for political content (Part VII)
Using LLMs to classify if social media posts are political or not (Part VII).
I’m working on a project that involves gathering social media posts from Bluesky and analyzing them. Part of that project requires knowing which posts are about political or social topics, and if so, what political side they support. Current ML classifiers don’t work that well out of the box, so I’m trying to create our own classification scheme using LLMs. I’m trying to use LLMs in order to classify Bluesky posts as either having political content or not, and if so, the political ideology, and I’ve found that LLMs work quite well for this task. I’ve used Llama3-8b and Llama3-70b via Groq so far, but are also open to experimenting with other open-source models as well (I have the on-prem infrastructure to host our own models, which is much cheaper at scale).
Previously, I confirmed that LLMs are promising for our classification task. We now want to replicate this. We previously synced the data for annotation. We then cleaned up the code to have a more robust ETL pipeline.
Now I want to optimize the LLM pipeline even more. We’ll want to be able to support running this on the scale of 20,000-50,000 posts per day. We want to do this so that we can run our classifier on firehose data. This will require tweaking our approach to support being able to classify more posts. A majority of our token usage comes from our approach towards adding “context” (using principles from retrieval-augmented generation, or RAG, see here).
Specifically, I’ll do the following:
- Convert JSON to YAML
- Pre-compute and caching context.
- Minimize requests to Bluesky for context generation as much as possible.
Experiment with converting JSON to YAML
First, I’ll explore converting JSON to YAML. This is inspired by this blog article from LinkedIn Engineering discussing their improved success with using YAML instead of JSON for their LLM applications. The efficiency gains can vary, but several (e.g., here and here) report good results when moving from JSON to YAML, due to speedups in parsing, reductions in token usage, and improved output formatting. For example, this reports that in some examples, we can cut tokens in half when using YAML (see below).

Adding a YAML format to the context generation
We already generate a dictionary for context. We initially just use a JSON version of that dictionary as the context for our prompt. Instead, we can simply dump this into a YAML format.
import json
import yaml
from typing import Literal
def generate_post_and_context_json(post: dict) -> dict:
"""Creates a JSON object with the post and its context.
The JSON object has the following format:
{
"post": {
"text": "The text of the post"
},
"context": {
"context_type": "context_details"
}
}
"""
context_details_list: list[tuple] = generate_context_details_list(post)
context_dict = {
# convert each Pydantic model to dict
context_type: context_details.dict()
for (context_type, context_details) in context_details_list
}
return {
"text": post["text"],
"context": context_dict
}
def generate_post_and_context(
post: dict,
format: str=Literal["json", "yaml"]
) -> str:
"""Generates a prompt that includes the post and its context."""
json_context: dict = generate_post_and_context_json(post=post)
if format == "json":
return json.dumps(json_context, indent=2)
elif format == "yaml":
return yaml.dump(json_context, sort_keys=False)
else:
raise ValueError("Unsupported format. Use 'json' or 'yaml'.")
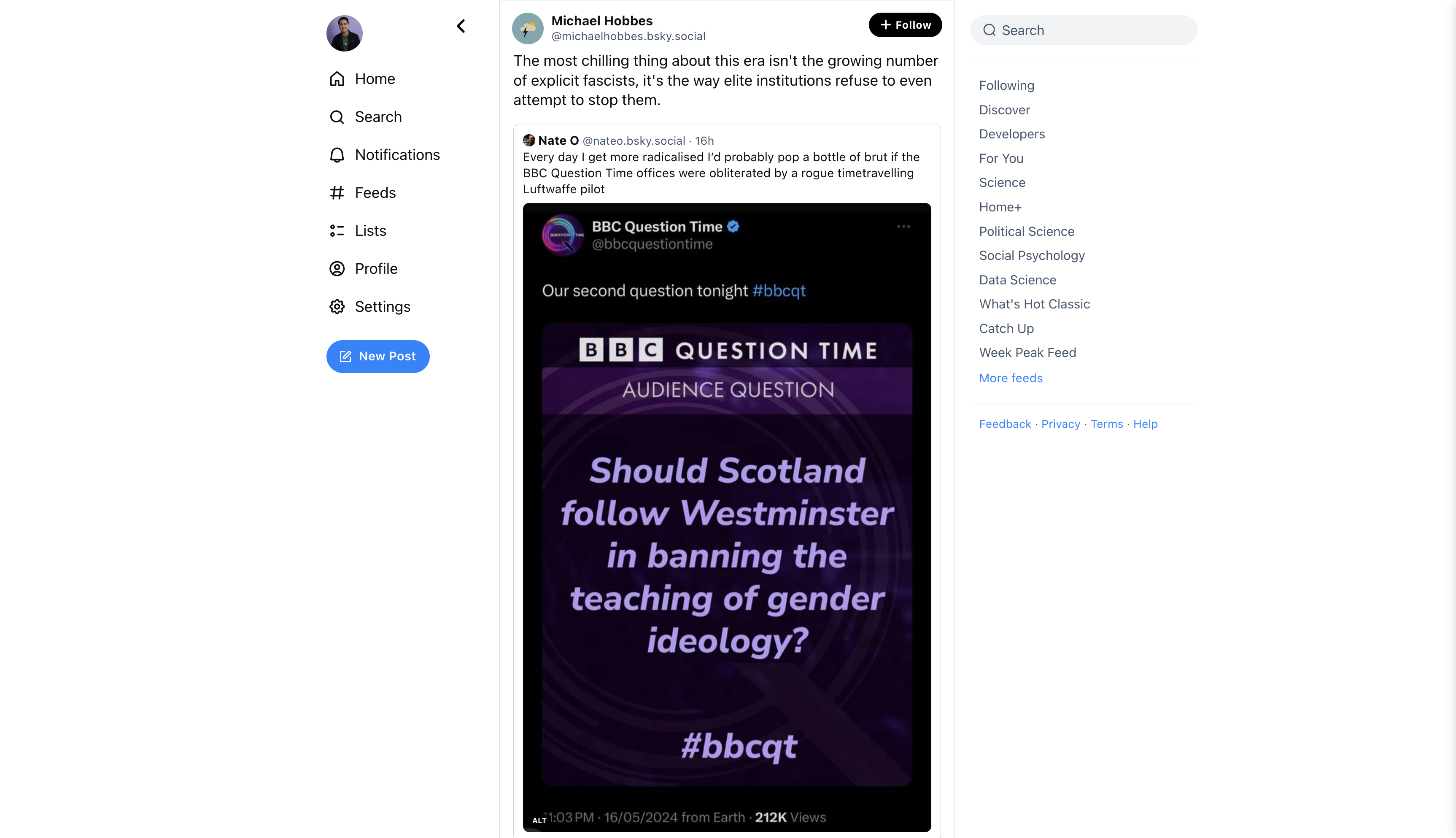
Let’s check how this makes our prompts look with the help of our demo app. Let’s try it on the following post from Bluesky. I am doing all this testing via Google Gemini.
Old prompt (using JSON):
Pretend that you are a classifier that predicts whether a post has sociopolitical content or not. Sociopolitical refers to whether a given post is related to politics (government, elections,
politicians, activism, etc.) or social issues (major issues that affect a large group of people, such as the economy, inequality, racism, education, immigration, human rights, the environment, etc.).
We refer to any content that is classified as being either of these two categories as "sociopolitical"; otherwise they are not sociopolitical. Please classify the following text as "sociopolitical" or
"not sociopolitical".
Then, if the post is sociopolitical, classify the text based on the political lean of the opinion or argument it presents. Your options are "democrat", "republican", or 'unclear'. You are analyzing
text that has been pre-identified as 'political' in nature. If the text is not sociopolitical, return "unclear".
Think through your response step by step.
Return in a JSON format in the following way:
{
"sociopolitical": <two values, 'sociopolitical' or 'not sociopolitical'>,
"political_ideology": <three values, 'democrat', 'republican', 'unclear'. If the post is not sociopolitical, return an empty string, "">,
"reason_sociopolitical": <optional, a 1 sentence reason for why the text is sociopolitical or not.>,
"reason_political_ideology": <optional, a 1 sentence reason for why the text has the given political ideology or is unclear. If the post is not sociopolitical, return an empty string, "">
}
All of the fields in the JSON must be present for the response to be valid, and the answer must be returned in JSON format.
Here is the post text that needs to be classified:
'''
<text>
The most chilling thing about this era isn't the growing number of explicit fascists, it's the way elite institutions refuse to even attempt to stop them.
'''
The following contains the post and its context:
'''
{'context': {'content_referenced_in_post': {'embedded_content_type': None,
'embedded_record_with_media_context': {'embed_image_alt_text': {'image_alt_texts': 'Our second question tonight #bbcqt\n'
'B\n'
'C\n'
'QUESTION TIME\n'
'AUDIENCE QUESTION\n'
'Should Scotland follow Westminster in banning the teaching of gender '
'ideology?\n'
'#bbcqt'},
'text': 'Every day I get more radicalised I’d probably pop a bottle of brut if the BBC Question Time offices were '
'obliterated by a rogue timetravelling Luftwaffe pilot'},
'has_embedded_content': True},
'post_author_context': {'post_author_is_reputable_news_org': False},
'post_tags_labels': {'post_labels': '', 'post_tags': ''},
'post_thread': {'thread_parent_post': {'embedded_image_alt_text': None, 'text': None}, 'thread_root_post': {'embedded_image_alt_text': None, 'text': None}},
'urls_in_post': {'embed_url_context': {'is_trustworthy_news_article': False, 'url': ''}, 'url_in_text_context': {'has_trustworthy_news_links': False}}},
'text': "The most chilling thing about this era isn't the growing number of explicit fascists, it's the way elite institutions refuse to even attempt to stop them."}
'''
Result of old prompt (using JSON):
{
"sociopolitical": "sociopolitical",
"political_ideology": "unclear",
"reason_sociopolitical": "The text discusses the rise of fascism and the failure of institutions to address it,
which are both sociopolitical issues.",
"reason_political_ideology": ""
}
Prompt token count: 764
Output token count: 73
New prompt (using YAML):
Pretend that you are a classifier that predicts whether a post has sociopolitical content or not. Sociopolitical refers to whether a given post is related to politics (government, elections,
politicians, activism, etc.) or social issues (major issues that affect a large group of people, such as the economy, inequality, racism, education, immigration, human rights, the environment, etc.).
We refer to any content that is classified as being either of these two categories as "sociopolitical"; otherwise they are not sociopolitical. Please classify the following text as "sociopolitical" or
"not sociopolitical".
Then, if the post is sociopolitical, classify the text based on the political lean of the opinion or argument it presents. Your options are "democrat", "republican", or 'unclear'. You are analyzing
text that has been pre-identified as 'political' in nature. If the text is not sociopolitical, return "unclear".
Think through your response step by step.
Return in a JSON format in the following way:
{
"sociopolitical": <two values, 'sociopolitical' or 'not sociopolitical'>,
"political_ideology": <three values, 'democrat', 'republican', 'unclear'. If the post is not sociopolitical, return an empty string, "">,
"reason_sociopolitical": <optional, a 1 sentence reason for why the text is sociopolitical or not.>,
"reason_political_ideology": <optional, a 1 sentence reason for why the text has the given political ideology or is unclear. If the post is not sociopolitical, return an empty string, "">
}
All of the fields in the JSON must be present for the response to be valid, and the answer must be returned in JSON format.
Here is the post text that needs to be classified:
'''
<text>
The most chilling thing about this era isn't the growing number of explicit fascists, it's the way elite institutions refuse to even attempt to stop them.
'''
The following contains the post and its context:
'''
text: The most chilling thing about this era isn't the growing number of explicit
fascists, it's the way elite institutions refuse to even attempt to stop them.
context:
content_referenced_in_post:
has_embedded_content: true
embedded_content_type: null
embedded_record_with_media_context:
text: "Every day I get more radicalised I\u2019d probably pop a bottle of brut\
\ if the BBC Question Time offices were obliterated by a rogue timetravelling\
\ Luftwaffe pilot"
embed_image_alt_text:
image_alt_texts: 'Our second question tonight #bbcqt
B
C
QUESTION TIME
AUDIENCE QUESTION
Should Scotland follow Westminster in banning the teaching of gender ideology?
#bbcqt'
urls_in_post:
url_in_text_context:
has_trustworthy_news_links: false
embed_url_context:
url: ''
is_trustworthy_news_article: false
post_thread:
thread_root_post:
text: null
embedded_image_alt_text: null
thread_parent_post:
text: null
embedded_image_alt_text: null
post_tags_labels:
post_tags: ''
post_labels: ''
post_author_context:
post_author_is_reputable_news_org: false
'''
Result of new prompt (using YAML):
{
"sociopolitical": "sociopolitical",
"political_ideology": "democrat",
"reason_sociopolitical": "The text discusses the rise of fascism and the failure of institutions to address it,
which are both sociopolitical issues.",
"reason_political_ideology": "The text criticizes elite institutions, which is a common theme in democratic
political discourse."
}
Prompt token count: 734
Output token count: 90
We see that the YAML uses slightly fewer tokens (reduces by 5%) than JSON format. We see that the output token is longer for YAML, but it’s because using the YAML format leads to a different classification (and therefore, a need to add a justification) than JSON format. It looks like the LLM can more easily parse and classify the input when a YAML file is passed in. This means that in addition to the reduction in token count, using YAML, especially when our context can instead exist in a nested JSON, means that we can better rely on accurate input tokenization and parsing.
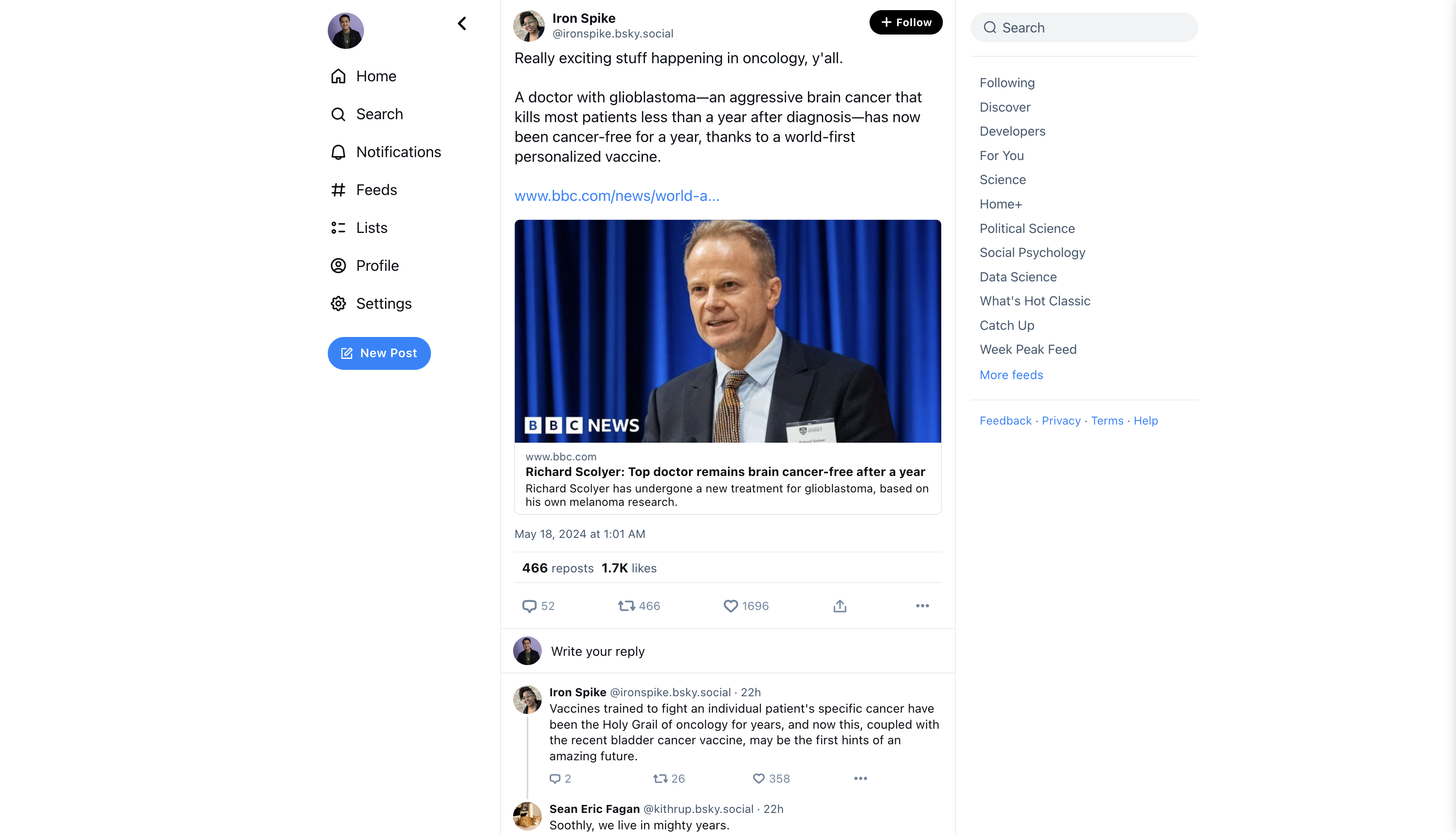
Let’s try another example:
Old prompt (using JSON):
Pretend that you are a classifier that predicts whether a post has sociopolitical content or not. Sociopolitical refers to whether a given post is related to politics (government, elections,
politicians, activism, etc.) or social issues (major issues that affect a large group of people, such as the economy, inequality, racism, education, immigration, human rights, the environment, etc.).
We refer to any content that is classified as being either of these two categories as "sociopolitical"; otherwise they are not sociopolitical. Please classify the following text as "sociopolitical" or
"not sociopolitical".
Then, if the post is sociopolitical, classify the text based on the political lean of the opinion or argument it presents. Your options are "democrat", "republican", or 'unclear'. You are analyzing
text that has been pre-identified as 'political' in nature. If the text is not sociopolitical, return "unclear".
Think through your response step by step.
Return in a JSON format in the following way:
{
"sociopolitical": <two values, 'sociopolitical' or 'not sociopolitical'>,
"political_ideology": <three values, 'democrat', 'republican', 'unclear'. If the post is not sociopolitical, return an empty string, "">,
"reason_sociopolitical": <optional, a 1 sentence reason for why the text is sociopolitical or not.>,
"reason_political_ideology": <optional, a 1 sentence reason for why the text has the given political ideology or is unclear. If the post is not sociopolitical, return an empty string, "">
}
All of the fields in the JSON must be present for the response to be valid, and the answer must be returned in JSON format.
Here is the post text that needs to be classified:
'''
<text>
Really exciting stuff happening in oncology, y'all.
A doctor with glioblastoma—an aggressive brain cancer that kills most patients less than a year after diagnosis—has now been cancer-free for a year, thanks to a world-first personalized vaccine.
www.bbc.com/news/world-a...
'''
The following contains the post and its context:
'''
{'context': {'content_referenced_in_post': {'embedded_content_type': None,
'embedded_record_with_media_context': {'description': 'Richard Scolyer has undergone a new treatment for glioblastoma, based on his own melanoma research.',
'title': 'Richard Scolyer: Top doctor remains brain cancer-free after a year'},
'has_embedded_content': True},
'post_author_context': {'post_author_is_reputable_news_org': False},
'post_tags_labels': {'post_labels': '', 'post_tags': ''},
'post_thread': {'thread_parent_post': {'embedded_image_alt_text': None, 'text': None}, 'thread_root_post': {'embedded_image_alt_text': None, 'text': None}},
'urls_in_post': {'embed_url_context': {'is_trustworthy_news_article': False, 'url': 'https://www.bbc.com/news/world-australia-69006713'},
'url_in_text_context': {'has_trustworthy_news_links': False}}},
'text': "Really exciting stuff happening in oncology, y'all.\n"
'\n'
'A doctor with glioblastoma—an aggressive brain cancer that kills most patients less than a year after diagnosis—has now been cancer-free for a year, thanks to a world-first personalized '
'vaccine.\n'
'\n'
'www.bbc.com/news/world-a...'}
'''
Result of old prompt (using JSON):
{
"sociopolitical": "not sociopolitical",
"political_ideology": "",
"reason_sociopolitical": "The text does not discuss politics or social issues.",
"reason_political_ideology": ""
}
Prompt token count: 780
Output token count: 56
New prompt (using YAML):
Pretend that you are a classifier that predicts whether a post has sociopolitical content or not. Sociopolitical refers to whether a given post is related to politics (government, elections,
politicians, activism, etc.) or social issues (major issues that affect a large group of people, such as the economy, inequality, racism, education, immigration, human rights, the environment, etc.).
We refer to any content that is classified as being either of these two categories as "sociopolitical"; otherwise they are not sociopolitical. Please classify the following text as "sociopolitical" or
"not sociopolitical".
Then, if the post is sociopolitical, classify the text based on the political lean of the opinion or argument it presents. Your options are "democrat", "republican", or 'unclear'. You are analyzing
text that has been pre-identified as 'political' in nature. If the text is not sociopolitical, return "unclear".
Think through your response step by step.
Return in a JSON format in the following way:
{
"sociopolitical": <two values, 'sociopolitical' or 'not sociopolitical'>,
"political_ideology": <three values, 'democrat', 'republican', 'unclear'. If the post is not sociopolitical, return an empty string, "">,
"reason_sociopolitical": <optional, a 1 sentence reason for why the text is sociopolitical or not.>,
"reason_political_ideology": <optional, a 1 sentence reason for why the text has the given political ideology or is unclear. If the post is not sociopolitical, return an empty string, "">
}
All of the fields in the JSON must be present for the response to be valid, and the answer must be returned in JSON format.
Here is the post text that needs to be classified:
'''
<text>
Really exciting stuff happening in oncology, y'all.
A doctor with glioblastoma—an aggressive brain cancer that kills most patients less than a year after diagnosis—has now been cancer-free for a year, thanks to a world-first personalized vaccine.
www.bbc.com/news/world-a...
'''
The following contains the post and its context:
'''
text: "Really exciting stuff happening in oncology, y'all.\n\nA doctor with glioblastoma\u2014\
an aggressive brain cancer that kills most patients less than a year after diagnosis\u2014\
has now been cancer-free for a year, thanks to a world-first personalized vaccine.\n\
\nwww.bbc.com/news/world-a..."
context:
content_referenced_in_post:
has_embedded_content: true
embedded_content_type: null
embedded_record_with_media_context:
title: 'Richard Scolyer: Top doctor remains brain cancer-free after a year'
description: Richard Scolyer has undergone a new treatment for glioblastoma,
based on his own melanoma research.
urls_in_post:
url_in_text_context:
has_trustworthy_news_links: false
embed_url_context:
url: https://www.bbc.com/news/world-australia-69006713
is_trustworthy_news_article: false
post_thread:
thread_root_post:
text: null
embedded_image_alt_text: null
thread_parent_post:
text: null
embedded_image_alt_text: null
post_tags_labels:
post_tags: ''
post_labels: ''
post_author_context:
post_author_is_reputable_news_org: false
'''
Result of new prompt (using YAML):
{
"sociopolitical": "not sociopolitical",
"political_ideology": "",
"reason_sociopolitical": "The text does not discuss politics or social issues.",
"reason_political_ideology": ""
}
Prompt token count: 762
Output token count: 56
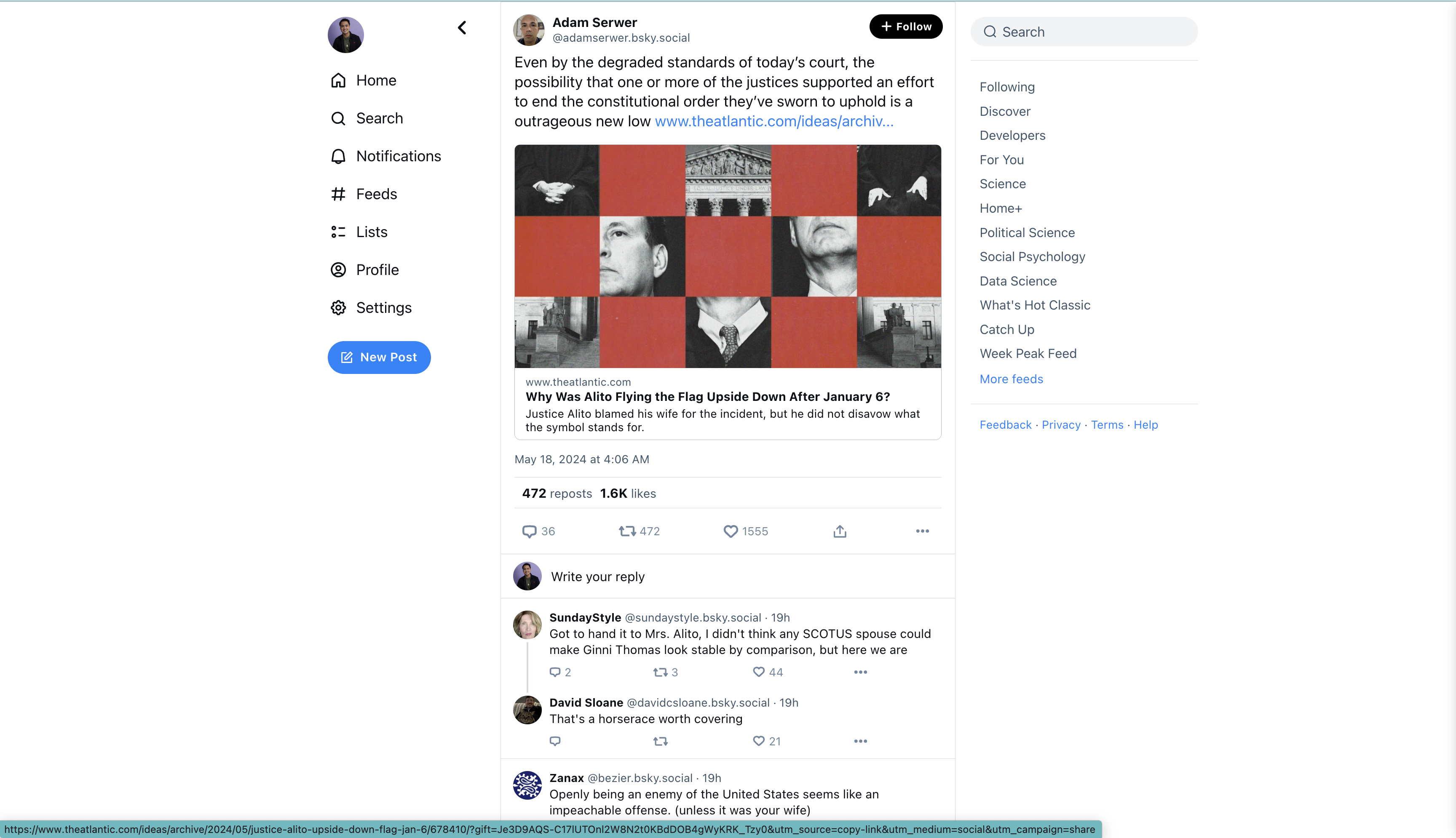
Let’s try a third example now.
Old prompt (using JSON):
Pretend that you are a classifier that predicts whether a post has sociopolitical content or not. Sociopolitical refers to whether a given post is related to politics (government, elections,
politicians, activism, etc.) or social issues (major issues that affect a large group of people, such as the economy, inequality, racism, education, immigration, human rights, the environment, etc.).
We refer to any content that is classified as being either of these two categories as "sociopolitical"; otherwise they are not sociopolitical. Please classify the following text as "sociopolitical" or
"not sociopolitical".
Then, if the post is sociopolitical, classify the text based on the political lean of the opinion or argument it presents. Your options are "democrat", "republican", or 'unclear'. You are analyzing
text that has been pre-identified as 'political' in nature. If the text is not sociopolitical, return "unclear".
Think through your response step by step.
Return in a JSON format in the following way:
{
"sociopolitical": <two values, 'sociopolitical' or 'not sociopolitical'>,
"political_ideology": <three values, 'democrat', 'republican', 'unclear'. If the post is not sociopolitical, return an empty string, "">,
"reason_sociopolitical": <optional, a 1 sentence reason for why the text is sociopolitical or not.>,
"reason_political_ideology": <optional, a 1 sentence reason for why the text has the given political ideology or is unclear. If the post is not sociopolitical, return an empty string, "">
}
All of the fields in the JSON must be present for the response to be valid, and the answer must be returned in JSON format.
Here is the post text that needs to be classified:
'''
<text>
Even by the degraded standards of today’s court, the possibility that one or more of the justices supported an effort to end the constitutional order they’ve sworn to uphold is a outrageous new low
www.theatlantic.com/ideas/archiv...
'''
The following contains the post and its context:
'''
{'context': {'content_referenced_in_post': {'embedded_content_type': None,
'embedded_record_with_media_context': {'description': 'Justice Alito blamed his wife for the incident, but he did not disavow what the symbol stands for.',
'title': 'Why Was Alito Flying the Flag Upside Down After January 6?'},
'has_embedded_content': True},
'post_author_context': {'post_author_is_reputable_news_org': False},
'post_tags_labels': {'post_labels': '', 'post_tags': ''},
'post_thread': {'thread_parent_post': {'embedded_image_alt_text': None, 'text': None}, 'thread_root_post': {'embedded_image_alt_text': None, 'text': None}},
'urls_in_post': {'embed_url_context': {'is_trustworthy_news_article': False,
'url': 'https://www.theatlantic.com/ideas/archive/2024/05/justice-alito-upside-down-flag-
jan-6/678410/?gift=Je3D9AQS-C17lUTOnl2W8N2t0KBdDOB4gWyKRK_Tzy0&utm_source=copy-link&utm_medium=social&utm_campaign=share'},
'url_in_text_context': {'has_trustworthy_news_links': False}}},
'text': 'Even by the degraded standards of today’s court, the possibility that one or more of the justices supported an effort to end the constitutional order they’ve sworn to uphold is a '
'outrageous new low www.theatlantic.com/ideas/archiv...'}
'''
New prompt (using YAML):
Pretend that you are a classifier that predicts whether a post has sociopolitical content or not. Sociopolitical refers to whether a given post is related to politics (government, elections,
politicians, activism, etc.) or social issues (major issues that affect a large group of people, such as the economy, inequality, racism, education, immigration, human rights, the environment, etc.).
We refer to any content that is classified as being either of these two categories as "sociopolitical"; otherwise they are not sociopolitical. Please classify the following text as "sociopolitical" or
"not sociopolitical".
Then, if the post is sociopolitical, classify the text based on the political lean of the opinion or argument it presents. Your options are "democrat", "republican", or 'unclear'. You are analyzing
text that has been pre-identified as 'political' in nature. If the text is not sociopolitical, return "unclear".
Think through your response step by step.
Return in a JSON format in the following way:
{
"sociopolitical": <two values, 'sociopolitical' or 'not sociopolitical'>,
"political_ideology": <three values, 'democrat', 'republican', 'unclear'. If the post is not sociopolitical, return an empty string, "">,
"reason_sociopolitical": <optional, a 1 sentence reason for why the text is sociopolitical or not.>,
"reason_political_ideology": <optional, a 1 sentence reason for why the text has the given political ideology or is unclear. If the post is not sociopolitical, return an empty string, "">
}
All of the fields in the JSON must be present for the response to be valid, and the answer must be returned in JSON format.
Here is the post text that needs to be classified:
'''
<text>
Even by the degraded standards of today’s court, the possibility that one or more of the justices supported an effort to end the constitutional order they’ve sworn to uphold is a outrageous new low
www.theatlantic.com/ideas/archiv...
'''
The following contains the post and its context:
'''
text: "Even by the degraded standards of today\u2019s court, the possibility that\
\ one or more of the justices supported an effort to end the constitutional order\
\ they\u2019ve sworn to uphold is a outrageous new low www.theatlantic.com/ideas/archiv..."
context:
content_referenced_in_post:
has_embedded_content: true
embedded_content_type: null
embedded_record_with_media_context:
title: Why Was Alito Flying the Flag Upside Down After January 6?
description: Justice Alito blamed his wife for the incident, but he did not
disavow what the symbol stands for.
urls_in_post:
url_in_text_context:
has_trustworthy_news_links: false
embed_url_context:
url: https://www.theatlantic.com/ideas/archive/2024/05/justice-alito-upside-down-flag-jan-6/678410/?gift=Je3D9AQS-C17lUTOnl2W8N2t0KBdDOB4gWyKRK_Tzy0&utm_source=copy-
link&utm_medium=social&utm_campaign=share
is_trustworthy_news_article: false
post_thread:
thread_root_post:
text: null
embedded_image_alt_text: null
thread_parent_post:
text: null
embedded_image_alt_text: null
post_tags_labels:
post_tags: ''
post_labels: ''
post_author_context:
post_author_is_reputable_news_org: false
'''
Result of old prompt (using JSON):
{
"sociopolitical": "sociopolitical",
"political_ideology": "democrat",
"reason_sociopolitical": "The post discusses the possibility that one or more Supreme Court justices supported an
effort to end the constitutional order, which is a sociopolitical issue.",
"reason_political_ideology": "The post expresses outrage at the possibility that justices supported an effort to end
the constitutional order, which is a view commonly held by Democrats."
}
Prompt token count: 807
Output token count: 105
Result of new prompt (using YAML):
{
"sociopolitical": "sociopolitical",
"political_ideology": "democrat",
"reason_sociopolitical": "The post discusses the possibility that one or more Supreme Court justices supported an
effort to end the constitutional order, which is a sociopolitical issue.",
"reason_political_ideology": "The post criticizes Justice Alito, who is a conservative justice, and suggests that he
may have supported an effort to overturn the constitutional order, which is a view commonly held by Democrats."
}
Prompt token count: 797
Output token count: 116
Let’s look at a series of posts and compare their token counts as well as their outputs.
| Link | Format | Token count (\% compared to JSON) | Has political content / Political ideology |
|---|---|---|---|
| https://bsky.app/profile/michaelhobbes.bsky.social/post/3ksowrqbmmk27 | JSON | 764 | sociopolitical / unclear |
| YAML | 734 (-3.7\%) | sociopolitical / democrat | |
| https://bsky.app/profile/ironspike.bsky.social/post/3ksp7b3vd3c2k | JSON | 780 | not sociopolitical / N/A |
| YAML | 762 (-2.3\%) | not sociopolitical / N/A | |
| https://bsky.app/profile/adamserwer.bsky.social/post/3kspjlucilo2b | JSON | 807 | sociopolitical / democrat |
| YAML | 797 (-1.2\%) | sociopolitical / democrat | |
| https://bsky.app/profile/jbouie.bsky.social/post/3kspg3yliqk22 | JSON | 771 | sociopolitical / democrat |
| YAML | 755 (-2.1\%) | sociopolitical / democrat | |
| https://bsky.app/profile/nkalamb.bsky.social/post/3ksplnntb7s2c | JSON | 749 | sociopolitical / unclear |
| YAML | 726 (-3.1\%) | sociopolitical / unclear | |
| https://bsky.app/profile/jbouie.bsky.social/post/3kspgd4c6pi2i | JSON | 748 | sociopolitical / democrat |
| YAML | 733 (-2.0\%) | sociopolitical / democrat | |
| https://bsky.app/profile/justinling.bsky.social/post/3kspnxjlsck27 | JSON | 818 | sociopolitical / democrat |
| YAML | 805 (-1.6\%) | sociopolitical / democrat | |
| https://bsky.app/profile/kendrawrites.bsky.social/post/3ksqeiyt3lt26 | JSON | 865 | sociopolitical / unclear |
| YAML | 826 (-4.5\%) | sociopolitical / unclear | |
| https://bsky.app/profile/paulwaldman.bsky.social/post/3kspvc5slhs27 | JSON | 743 | sociopolitical / democrat |
| YAML | 730 (-1.7\%) | sociopolitical / democrat | |
| https://bsky.app/profile/tkingfisher.bsky.social/post/3kspbodb6oc2l | JSON | 747 | sociopolitical / democrat |
| YAML | 735 (-1.6\%) | sociopolitical / democrat |
We can see that using the YAML format consistently uses 2\%-3\% fewer tokens than the JSON format. A small amount but it is across all inputs so we should adopt this format for the inputs.
Investigating fetching results from the LLM in YAML format.
Adding defensive fixes for errors in YAML output formatting.
Pre-compute and caching context
Let’s also pre-compute the context and cache it so we don’t have to re-compute it over time.
First, I’ll create Pydantic models in order to verify the expected schemas for the context.
class ContextModel(BaseModel):
context_referenced_in_post: EmbeddedContextContextModel = Field(
..., description="The context referenced in the post."
)
urls_in_post: PostLinkedUrlsContextModel = Field(
..., description="The URLs in the post."
)
post_thread: ThreadContextModel = Field(
..., description="The context of the thread of the post."
)
post_tags_labels: PostTagsLabelsContextModel = Field(
..., description="The tags and labels of the post."
)
post_author_context: AuthorContextModel = Field(
..., description="The context of the author of the post."
)
class FullPostContextModel(BaseModel):
"""Model for the context of a post."""
uri: str = Field(..., description="The URI of the post.")
context: ContextModel = Field(..., description="The context of the post.")
text: str = Field(..., description="The text of the post.")
timestamp: str = Field(..., description="The timestamp of the post.")
The code to generate the context as a dictionary then becomes:
def generate_post_and_context_json(post: dict) -> dict:
"""Creates a JSON object with the post and its context.
The JSON object has the following format:
{
"post": {
"text": "The text of the post"
},
"context": {
"context_type": "context_details"
}
}
"""
context_details_list: list[tuple] = generate_context_details_list(post)
context_dict = {
# convert each Pydantic model to dict
context_type: context_details.dict()
for (context_type, context_details) in context_details_list
}
full_context_dict = {
"uri": post["uri"],
"text": post["text"],
"context": context_dict,
"timestamp": current_datetime_str
}
return FullPostContextModel(**full_context_dict).dict()
I wasn’t sure what to use for the DB for this portion. I think that I’ll eventually move to NoSQL so that I have the flexibility to make adjustments to what fields to include when calculating context as well as making it easier to re-calculate specific nested fields within the context dictionary. But, for the sake of building quickly, I’ll use SQLite (and peewee for my ORM).
db = peewee.SqliteDatabase(SQLITE_DB_PATH)
db_version = 2
conn = sqlite3.connect(SQLITE_DB_PATH)
cursor = conn.cursor()
class BaseModel(peewee.Model):
class Meta:
database = db
class FullPostContext(BaseModel):
"""Full context for a post."""
uri = peewee.CharField(unique=True)
context = peewee.TextField() # will need to serialize
text = peewee.TextField()
timestamp = peewee.TextField()
def insert_post_context(post: FullPostContextModel):
"""Insert a post context into the database."""
with db.atomic():
FullPostContext.create(
uri=post.uri,
context=post.context.json(),
text=post.text,
timestamp=post.timestamp
)
def get_post_context(uri: str) -> Optional[FullPostContextModel]:
"""Get a post context from the database."""
post = FullPostContext.get_or_none(FullPostContext.uri == uri)
if post:
return FullPostContextModel(
uri=post.uri,
context=post.context,
text=post.text,
timestamp=post.timestamp
)
return None
Now we can test this. We’ll connect this to the prompt generation code. We’ll create the context if it doesn’t exist, else fetch from the database.
def generate_post_context(post: dict) -> FullPostContextModel:
"""Creates context of the post."""
context_details_list: list[tuple] = generate_context_details_list(post)
context_dict = {
# convert each Pydantic model to dict
context_type: context_details.dict()
for (context_type, context_details) in context_details_list
}
full_context_dict = {
"uri": post["uri"],
"text": post["text"],
"context": context_dict,
"timestamp": current_datetime_str
}
return FullPostContextModel(**full_context_dict)
def get_or_create_post_and_context_json(post: dict) -> dict:
"""Gets or creates the context for a post."""
uri: str = post["uri"]
post_context: Optional[FullPostContextModel] = get_post_context(uri=uri)
if not post_context:
print(f"Creating context for post {uri}")
post_context: FullPostContextModel = generate_post_context(post)
insert_post_context(post_context)
return post_context.dict()
Now we update our helper for adding the context to our prompt:
def generate_context_from_post(
post: dict,
format: str = Literal["json", "yaml"],
pformat_output: bool = True
) -> str:
"""Generates the context from the post."""
json_context: dict = get_or_create_post_and_context_json(post=post)
if format == "json":
res: dict = json_context
if pformat_output:
res: str = pformat(res, width=200)
elif format == "yaml":
# yes having multiple typings is weird
res: str = yaml.dump(json_context, sort_keys=False)
else:
raise ValueError("Unsupported format. Use 'json' or 'yaml'.")
full_context = f"""
The following contains the post and its context:
'''
{res}
'''
"""
return full_context
To verify that the above code work, we test for the following cases.
- Test 1: brand new post
- Verify that if context for post URI doesn’t exist, context is generated and inserted to DB.
- Test 2: same post as Test 1
- Verify that URI exists in DB and that context is correctly pulled from the database.
Now that those have been verified, we can move on.
Minimize requests to Bluesky for context generation as much as possible
We look at any other posts that referenced in a given Bluesky post. We look at three such cases:
- A post that is an embed of another post. This is a Bluesky “quote tweet”, where one post is referencing another post.
- If a post is part of a thread, the parent post, or the post that the current post is replying to.
- If a post is part of a thread, the root post, or the very first post in the thread.
For all of these cases, we hydrate the referenced post from Bluesky and grab information as needed. We should store these posts in our database so that we don’t have to duplicate requests.
First, we create a new function that either gets a record from the database, given the record uri, or requests it from the Bluesky API:
def get_or_request_embedded_record_with_author(
record_uri: str, insert_new_record_bool: bool = True
) -> dict:
"""Fetches the record associated with a record URI from the DB or, if it
doesn't exist, fetches it from the Bluesky API and then stores it in DB.
"""
record_dict: dict = get_record_as_dict_by_uri(record_uri)
if record_dict:
print(f"Fetched record with URI {record_uri} from DB.")
record_with_author: TransformedRecordWithAuthorModel = (
TransformedRecordWithAuthorModel(**record_dict)
)
else:
print(f"Fetching record with URI {record_uri} from Bluesky API.")
record_with_author: TransformedRecordWithAuthorModel = (
get_record_with_author_given_post_uri(record_uri)
)
if insert_new_record_bool:
insert_new_record(record_with_author)
return record_with_author.dict()
This simplifies the way that we get information about posts referenced in a given Bluesky post:
def process_record_context(record_uri: str) -> RecordContextModel:
"""Processes the context for any records that are referenced in a post.
This includes posts that are being referenced by another post as well as
posts that are part of the thread that a post is a part of.
For now we'll just return the text and the image of these posts.
Doesn't recursively process embedded records (e.g., if the post references
another post that references another post, etc., the processing only goes
down 2 layers deep). We enforce this by getting only the text and image
of the embedded record, not if the embedded record has its own embedded
record within it.
"""
if not record_uri:
return RecordContextModel()
record: dict = get_or_request_embedded_record_with_author(record_uri)
text = record.text
embed_dict = record.embed
embed_image_alt_text = None
if embed_dict:
if embed_dict["has_image"]:
embed_image_alt_text: ImagesContextModel = (
process_images_embed(embed_dict)
)
return RecordContextModel(
text=text, embed_image_alt_text=embed_image_alt_text
)
Summary
Now with these modified changes as well as previous changes to include batching, we should see more efficient inference due to fewer tokens being used and less duplicated requests to Bluesky being made.