
Research updates, 2024-05-31
Research updates, 2024-05-31
Today, I worked on the following:
- Met with Research Support.
- Removed my databases from Git tracking.
- Hunted down problems with the preprocessing pipeline.
- Thought through scalability concerns.
- Built a batch inference pipeline for classifications with the Perspective API.
Met with Research Support
Removed my databases from Git tracking
I keep accidentally overwriting my local databases with the old versions that I’ve accidentally saved to Github. I already have file backups set on a cron job so this isn’t the worst, but I don’t want to restore from backups if possible. So, I removed them from Git tracking. I found this documentation helpful (as well as ChatGPT, of course, but for any “rm” stuff, I like to check the docs to be 100% sure that it does what I think it will do).
git rm --cached synced_record_posts.db
git rm --cached filtered_posts.db
git rm --cached '*.db'
From looking at VSCode, it looks like the .db files are no longer being tracked, so that’s good!
![]()
Hunted down problems with the preprocessing pipeline
I checked the preprocessed posts database and it had n~6,600 posts, so it seemed like a duplicate of yesterday’s problems. I investigated and it looks like when I reset my git commits in order to undo when I committed very large files into Git, I accidentally reset too far and I removed the patches that I had put in place to initially fix this issue. Luckily this wasn’t too bad to figure out, and like yesterday I made the changes and deleted the database to rebuild it from scratch.
One change I did make though was add deduping prior to insertion. I’ve been explicitly ignoring any errors in order to avoid duplicate URI problems and overwrite them, but I realize that this actually obfuscates a lot of possible problems, such as this one, where the writes silently failed.
FilteredPreprocessedPosts.insert_many(
posts_to_insert_dicts
).on_conflict_ignore().execute()
Instead, I removed the on_conflict_ignore() and just added deduping instead. Not sure how it scales, might need a Bloom filter at some point, but it works for now:
def get_previously_filtered_post_uris() -> set[str]:
"""Get previous IDs from the DB."""
previous_ids = FilteredPreprocessedPosts.select(FilteredPreprocessedPosts.uri) # noqa
return set([p.uri for p in previous_ids])
def dedupe_posts(
posts: list[FilteredPreprocessedPostModel]
) -> list[FilteredPreprocessedPostModel]:
"""
Dedupes posts to make sure that we don't insert any duplicates.
Note: will need to see how this scales, especially at the scale of millions
of posts.
"""
existing_uris: set[str] = get_previously_filtered_post_uris()
seen_uris = set()
seen_uris.update(existing_uris)
unique_posts = []
for post in posts:
if post.uri not in seen_uris:
seen_uris.add(post.uri)
unique_posts.append(post)
logger.info(f"Total posts to attempt to insert: {len(posts)}")
logger.info(f"Total unique posts: {len(unique_posts)}")
logger.info(f"Total duplicates: {len(posts) - len(unique_posts)}")
return unique_posts
def batch_create_filtered_posts(
posts: list[FilteredPreprocessedPostModel]
) -> None:
"""Batch create filtered posts in chunks.
Uses peewee's chunking functionality to write posts in chunks. Adds
deduping on URI as well. This should already be done in various upstream
places but is here for redundancy.
"""
total_posts = FilteredPreprocessedPosts.select().count()
logger.info(f"Total number of posts before inserting into preprocessed posts database: {total_posts}") # noqa
unique_posts: list[FilteredPreprocessedPostModel] = dedupe_posts(posts)
with db.atomic():
for idx in range(0, len(unique_posts), DEFAULT_BATCH_WRITE_SIZE):
posts_to_insert = unique_posts[idx:idx + DEFAULT_BATCH_WRITE_SIZE]
posts_to_insert_dicts = [post.dict() for post in posts_to_insert]
FilteredPreprocessedPosts.insert_many(
posts_to_insert_dicts
).execute()
total_posts = FilteredPreprocessedPosts.select().count()
logger.info(f"Total number of posts after inserting into preprocessed posts database: {total_posts}") # noqa
Thought through scalability concerns
Now that I’m building out the classification pipelines, I need to start thinking more deeply about scalability. I suppose that this was true for the preprocessing pipeline, but that is more narrowly scoped and I’m more confident that that will just work OK as is. It’s unlikely that I can classify all the posts in one go, (more true for LLM than perspective API), so I’m trying to work through a few ideas.
One idea is that during processing, I should sort posts by date ascending so that I process the earliest posts first, and then record the timestamp as the timestamp of the last post processed, unless I get through all the posts, in which case it should be the timestamp in which the classification was run. Another strategy is to match the URIs against the URIs of posts that have been processed, in order to see what’s not been processed yet. Yet another strategy is keeping the posts in a cache and then evicting them once they’ve been classified.
Now that I think about it, the simplest option might be to add a field, latest_preprocessed_post, or something like that, that tracks the latest preprocessed timestamp of a post that’s been classified. That way, I can split up a batch of 100,000 posts into 10 batches, for example, and run those jobs.
If I’m going to batch, I need an orchestrator file that can send jobs out in batches, and then check the status of those jobs, and then collect the results. This is more true for the LLM than the Perspective API, but it is something to keep in mind.
I think that what I actually need is to use the latest preprocessing timestamp of the latest completely successfully run batch of posts. That is the latest guaranteed source of truth, and I can backfill everything more recent than that, even if it leads to some duplicate processing.
I could do a simple URI lookup I suppose, but I would have to cache those results and then compute it offline.
For the current problem, I only have ~n=100,000 posts, so scale-wise, this shouldn’t be a problem, at least for now. I might have to build this in in order to use the LLMs on KLC, but I’ll deal with that when I get there I suppose.
My current concern is that since I have to split a single job into a batch job, I need a way to account for the case that one of those jobs fails, and when it fails, how do I make sure that the posts that weren’t processed will be processed by a future job. I think that the most promising option is just recording each classification job and recording the ID of the job, the job status, and the min and max preprocessing_timestamp of a given job, so that if the job fails, I can just pull those same posts and re-do inference again. Another idea that I think is promising is having an offline job that goes through the preprocessed database and checks to see which posts were preprocessed earlier than the latest classification job, since these are posts that we must have tried to classify before but somehow failed, and adding those to a cache of some sort that we can then pull from in a subsequent classification job.
But, I might, in the coming weeks, have to really investigate scalability concerns to make sure that everything works as intended. Right now I just need something that works for the present problem. For a naive implementation, I’ll just use the latest classification timestamp as my filter and then assume that when I split up a job into multiple batches, that it won’t fail. I think that in Summer 2024, I’ll be doing lots of engineering-related stuff that’s been on the backlog, like observability, adding testing, and things like that.
Built a batch inference pipeline for classifications with the Perspective API
I’m now working on building a batch inference pipeline with the Perspective API.
Checking current rate limits
First, I need to check my Google Cloud project to see what my current rate limits are for the Perspective API.
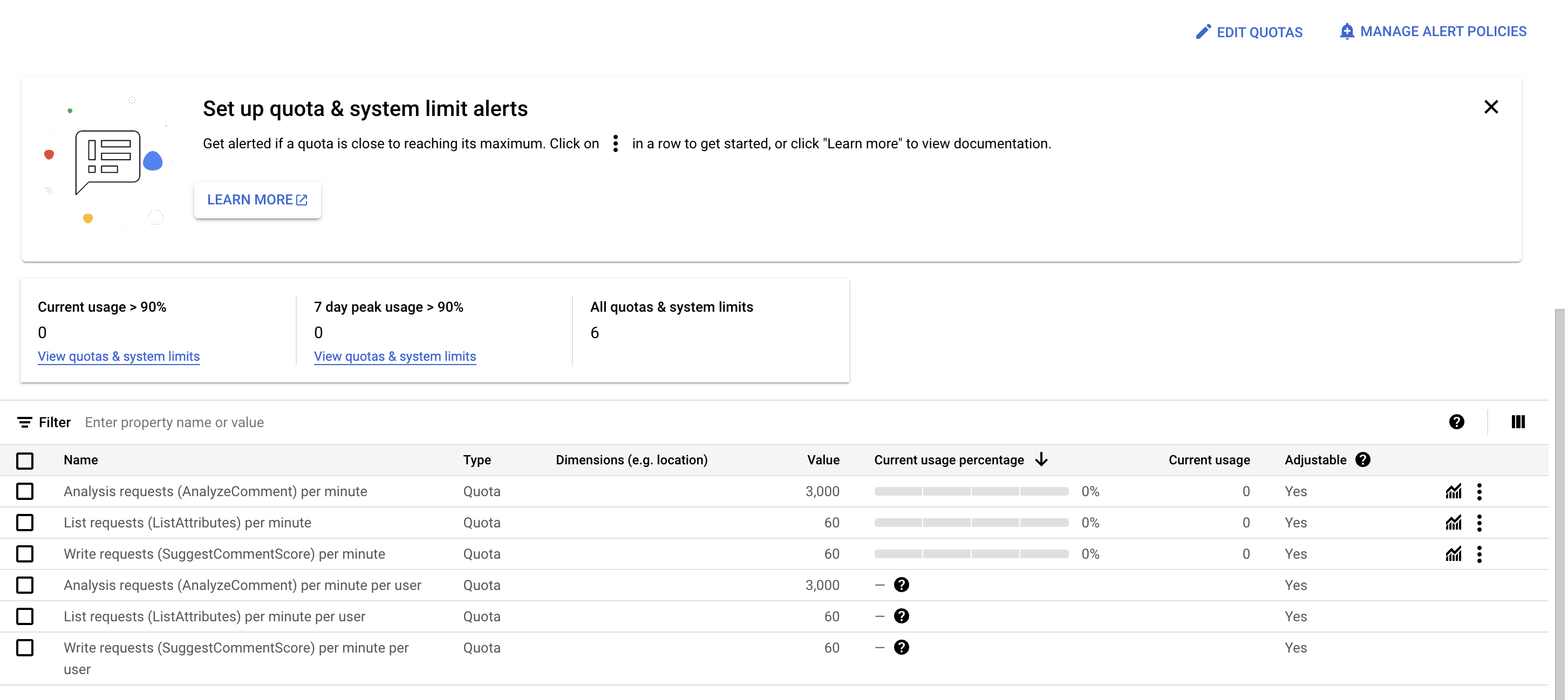
It looks like for the AnalyzeComment endpoint, which is what actually does the inference step, the current limit is 3,000QPM. This is OK for now, but for our use case of analyzing n~150,000 posts in our pilot, that we’d need about 1 hour to run inference. This is OK, though this means that we’ll have to build in some scale, such as sensible error-handling as well as writing the results to the database over time.
Our current limit works out to 50QPS. I requested to double that rate limit to 100QPS. This is what Tin, the lead PM at Jigsaw told us, during a meeting, would be OK to request without additional information. I’ll work with the 50QPS limit and then just double that when I get confirmation of the approved rate limit increase.
Also, sidebar, it looks like Jigsaw is working on adding context to their comment classifications (see here and here). It’s funny that in looking at how it works, it seems like the idea is similar to the prototype that I developed and described last month here. I’m interested in seeing how it works, but at a high-level, I can probably guess some of the initial things that have been tried. Hopefully they get this to work on the Perspective API so that I can make use of it.
Here’s how Jigsaw describes the context:

This gives me reassurance that I’m directionally working on an interesting and impactful idea, since a team at Google is working on a similar idea as well. I hav a few ideas already about how I want to build it, though I probably won’t be able to get back to it until July at the earliest.
Adding async and batching to inference
I already have a function that sends a request to the Perspective API and gets the labels.
def classify(
text: str, attributes: Optional[dict] = default_requested_attributes
) -> dict:
"""Classify text using all the attributes from the Google Perspectives API.""" # noqa
response = request_comment_analyzer(
text=text, requested_attributes=attributes
)
response_obj = json.loads(response)
if "error" in response_obj:
return {"error": response_obj["error"]}
classification_probs_and_labels = {}
for attribute, labels in attribute_to_labels_map.items():
if attribute in response_obj["attributeScores"]:
prob_score = (
response_obj["attributeScores"][attribute]["summaryScore"]["value"] # noqa
)
classification_probs_and_labels[labels["prob"]] = prob_score
classification_probs_and_labels[labels["label"]
] = 0 if prob_score < 0.5 else 1
return classification_probs_and_labels
I built my own version of async batch classifications. I want to be able to classify async so that I can send multiple requests without having to wait for the results of a given request to be returned. Doing this instead of a naive serial for-loop implementation means that I can do other computations and send more requests without being delayed by I/O.
async def single_batch_classify_texts(
batch_texts: list[str],
attributes: Optional[dict] = default_requested_attributes
) -> list[tuple[str, dict]]:
"""Runs batch classification for a batch of texts. Runs them async
and then collects the results at once.
"""
async with aiohttp.ClientSession():
tasks = []
for text in batch_texts:
tasks.append(
classify(text=text, attributes=attributes)
)
labels: dict = await asyncio.gather(*tasks)
return list[zip(batch_texts, labels)]
async def batch_classify_texts(
texts: list[str],
attributes: Optional[dict]=default_requested_attributes,
batch_size: Optional[int]=50,
seconds_delay_per_batch: Optional[float]=1.0
):
"""Runs batch classification for a series of batches of texts.
Splits the list of texts into batches and then runs the classification
for each batch asynchronously.
"""
batches: list[list[str]] = create_batches(
iterable=texts, batch_size=batch_size
)
results = []
for batch in batches:
results.extend(
await single_batch_classify_texts(
batch_texts=batch, attributes=attributes
)
)
await asyncio.sleep(seconds_delay_per_batch)
return results
def run_batch_classification(
texts: list[str],
attributes: Optional[dict]=default_requested_attributes,
batch_size: Optional[int]=50,
seconds_delay_per_batch: Optional[float]=1.0
):
"""Runs batch classification for a series of batches of texts."""
# TODO: should probably include any error-handling or similar logic
# here.
return asyncio.run(
batch_classify_texts(
texts=texts,
attributes=attributes,
batch_size=batch_size,
seconds_delay_per_batch=seconds_delay_per_batch
)
)
This is nice, and could probably work, but with the additional overhead of many small HTTP requests. I’ll revert to this if nothing else works, but it seems like there’s a way to create batch requests via the Google API client. I’ll try that first and see how it does.
def create_perspective_request(text):
return {
'comment': {'text': text},
'languages': ['en'],
'requestedAttributes': default_requested_attributes
}
async def process_perspective_batch(requests, responses):
"""Process a batch of requests in a single query.
See https://googleapis.github.io/google-api-python-client/docs/batch.html
for more details
"""
batch = BatchHttpRequest()
def callback(request_id, response, exception):
if exception is not None:
print(f"Request {request_id} failed: {exception}")
responses.append(None)
else:
response_str = json.dumps(response)
response_obj = json.loads(response_str)
if "error" in response_obj:
print(f"Request {request_id} failed: {response_obj['error']}")
responses.append(None)
classification_probs_and_labels = {}
for attribute, labels in attribute_to_labels_map.items():
if attribute in response_obj["attributeScores"]:
prob_score = (
response_obj["attributeScores"][attribute]["summaryScore"]["value"] # noqa
)
classification_probs_and_labels[labels["prob"]] = prob_score # noqa
classification_probs_and_labels[labels["label"]] = 0 if prob_score < 0.5 else 1
responses.append(classification_probs_and_labels)
for _, request in enumerate(requests):
batch.add(
google_client.comments().analyze(body=request), callback=callback
)
batch.execute()
async def batch_classify_texts(
texts: list[str],
batch_size: Optional[int]=DEFAULT_BATCH_SIZE,
seconds_delay_per_batch: Optional[float]=1.0
):
request_payloads: list[dict] = [
create_perspective_request(text) for text in texts
]
request_payload_batches: list[list[dict]] = create_batches(
iterable=request_payloads, batch_size=batch_size
)
responses: list[dict] = []
for batch in request_payload_batches:
await process_perspective_batch(batch, responses)
await asyncio.sleep(seconds_delay_per_batch)
return responses
def run_batch_classification(
texts: list[str],
batch_size: Optional[int]=DEFAULT_BATCH_SIZE,
seconds_delay_per_batch: Optional[float]=1.0
):
loop = asyncio.get_event_loop()
responses = loop.run_until_complete(
batch_classify_texts(
texts=texts,
batch_size=batch_size,
seconds_delay_per_batch=seconds_delay_per_batch
)
)
return responses
I’ll also delete the label_* (e.g., label_toxic) fields in my Pydantic models and table schemas for the Perspective API. What we get from the API is just the probabilities, and I’m using an artificial decision boundary of p=0.5, when I can set that myself after the fact and what we really care about for now is the probabilities. Plus, p=0.5 isn’t even strictly the best boundary to use for binary problems, and in this case for example, Jigsaw even says to use a threshold higher than p=0.5 for measuring toxicity in production (think they mention p=0.8 or p=0.9 as an appropriate threshold).
class PerspectiveApiLabelsModel(BaseModel):
"""Stores results of classifications from Perspective API.
Uses all the available attributes from the Perspective API, so that we have
this data in the future as well for exploratory analysis.
"""
uri: str = Field(..., description="The URI of the post.")
text: str = Field(..., description="The text of the post.")
was_successfully_labeled: bool = Field(..., description="Indicates if the post was successfully labeled by the Perspective API.")
reason: Optional[str] = Field(default=None, description="Reason for why the post was not labeled successfully.")
label_timestamp: str = Field(..., description="Timestamp when the post was labeled (or, if labeling failed, when it was attempted).")
prob_toxic: Optional[float] = Field(default=None, description="Probability of toxicity.")
prob_severe_toxic: Optional[float] = Field(default=None, description="Probability of severe toxicity.")
prob_identity_attack: Optional[float] = Field(default=None, description="Probability of identity attack.")
prob_insult: Optional[float] = Field(default=None, description="Probability of insult.")
prob_profanity: Optional[float] = Field(default=None, description="Probability of profanity.")
prob_threat: Optional[float] = Field(default=None, description="Probability of threat.")
prob_affinity: Optional[float] = Field(default=None, description="Probability of affinity.")
prob_compassion: Optional[float] = Field(default=None, description="Probability of compassion.")
prob_constructive: Optional[float] = Field(default=None, description="Probability of constructive.")
prob_curiosity: Optional[float] = Field(default=None, description="Probability of curiosity.")
prob_nuance: Optional[float] = Field(default=None, description="Probability of nuance.")
prob_personal_story: Optional[float] = Field(default=None, description="Probability of personal story.")
prob_reasoning: Optional[float] = Field(default=None, description="Probability of reasoning.")
prob_respect: Optional[float] = Field(default=None, description="Probability of respect.")
prob_alienation: Optional[float] = Field(default=None, description="Probability of alienation.")
prob_fearmongering: Optional[float] = Field(default=None, description="Probability of fearmongering.")
prob_generalization: Optional[float] = Field(default=None, description="Probability of generalization.")
prob_moral_outrage: Optional[float] = Field(default=None, description="Probability of moral outrage.")
prob_scapegoating: Optional[float] = Field(default=None, description="Probability of scapegoating.")
prob_sexually_explicit: Optional[float] = Field(default=None, description="Probability of sexually explicit.")
prob_flirtation: Optional[float] = Field(default=None, description="Probability of flirtation.")
prob_spam: Optional[float] = Field(default=None, description="Probability of spam.")
Final thoughts
I did a lot of engineering today as well as a lot of planning for scalability. I had to consider the tradeoffs between getting something done for the pilot study for now versus building for the scalability that will soon come. Learned a lot today, which is good. I also will start using the LLMs on the compute cluster soon, which will mean learning a lot about GPUs and LLM inference without APIs.