
First impressions of using Google Antigravity on a real project
First impressions of using Google Antigravity on a real project
I figured that I could try Google Antigravity on a live project and see how it did and how I would have done it on Cursor.
Problem that I’m trying to work on
I have an existing repo in Github where I put one-off experiments before graduating them to their own repos. Right now, I’m experimenting with AI agents for social science simulations. I want to see how well Antigravity (and really, any coding agent) can one-shot this task. I don’t think it’s really complicated, but it does have a few moving parts that an AI agent would have to traverse, plus it’ll be a slightly longer-running task.
Setting up Antigravity
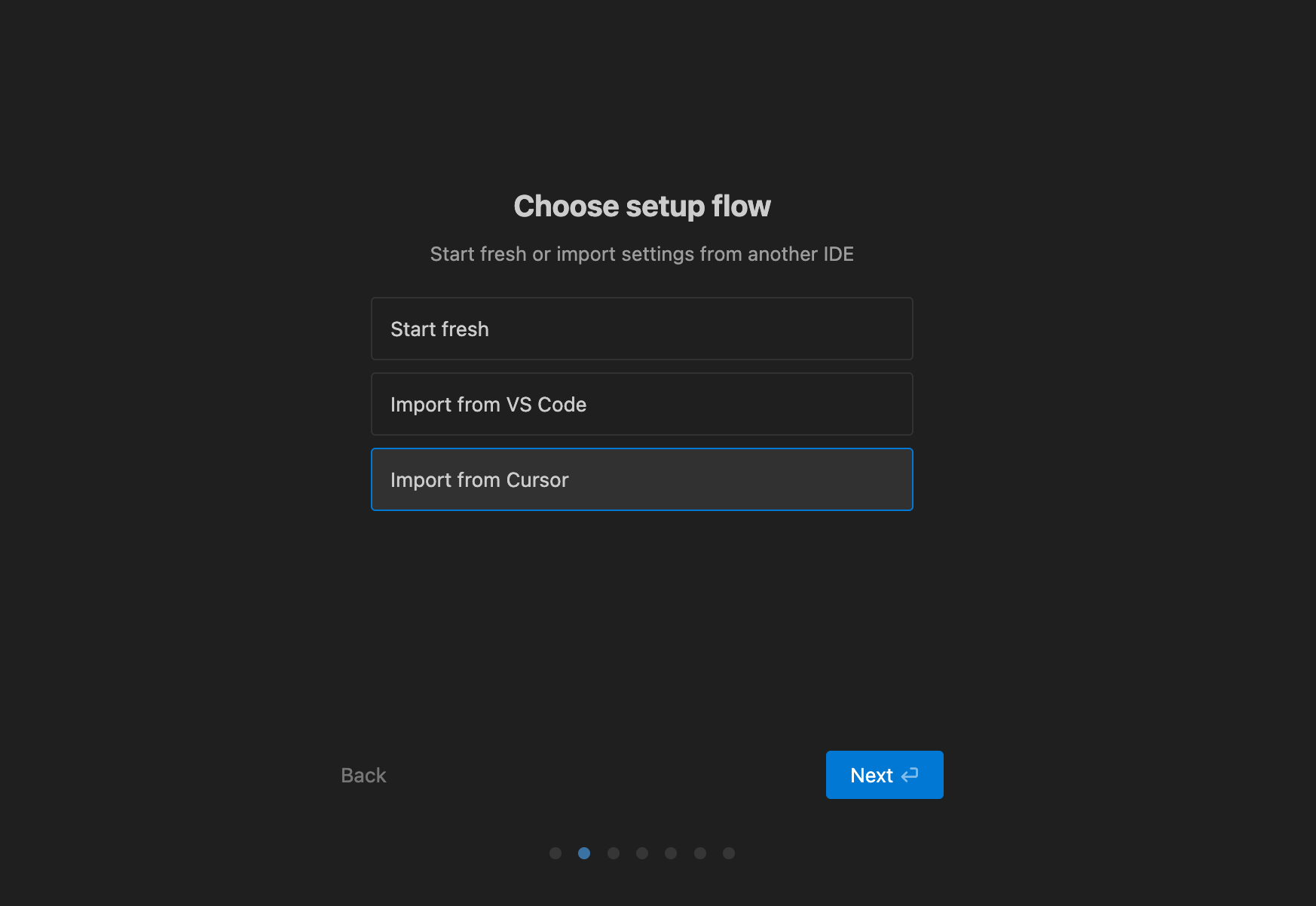
Seamless setup
I could directly import my existing settings from Cursor (which itself, during my setup, allowed me to import from VSCode).
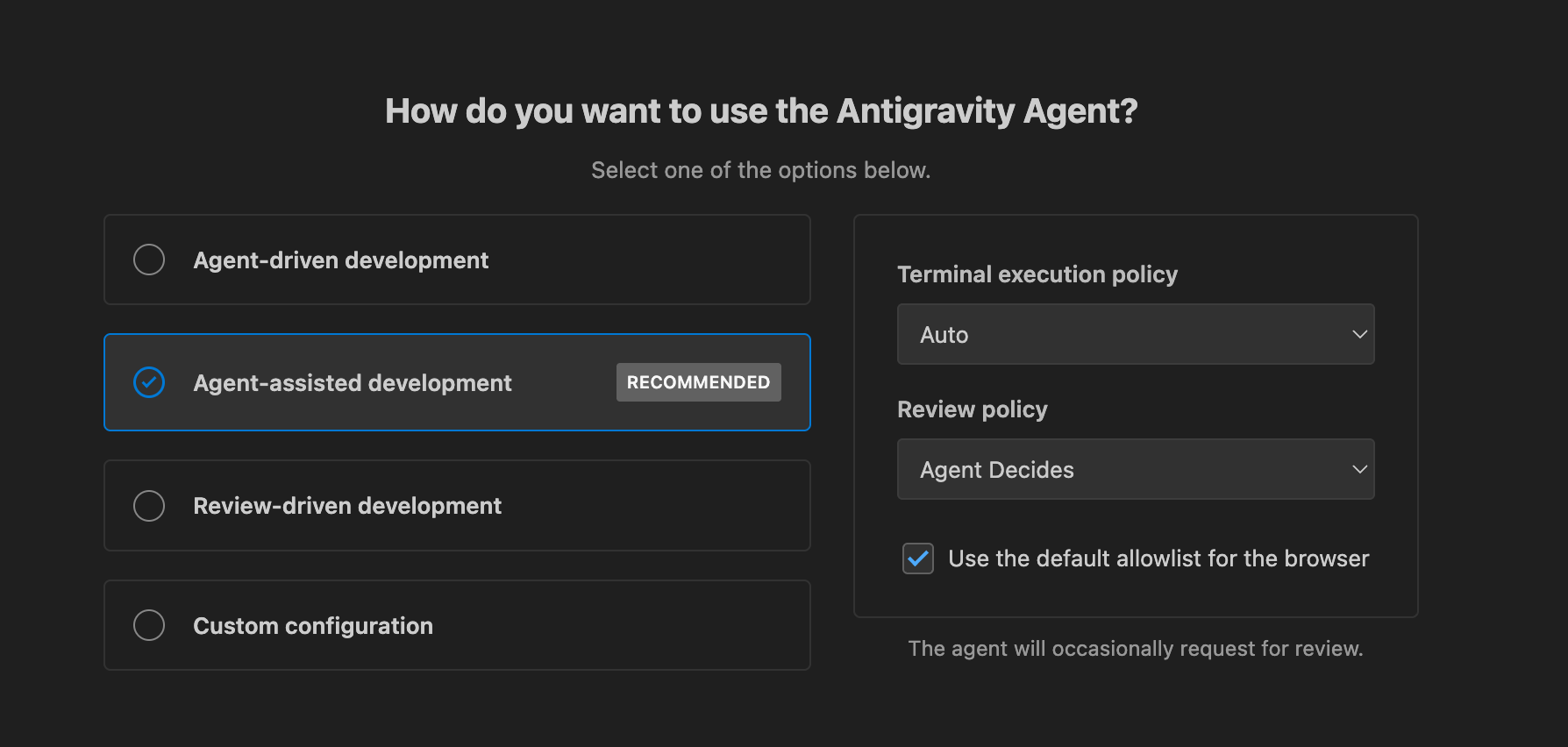
A lot of thought was put into the common use cases for Antigravity
I’m a big fan of the suggested settings here for how I want to use Antigravity. I think that “Agent-assisted development” is a good default, where the agent decides when it needs me and otherwise it runs autonomously. But it’s clear that you can use it however you’d like and you can customize the degree of control you have over the agents.
Artifacts and browser capabilities are first-class objects in Antigravity
I like that artifacts and the browser both have their own dedicated interfaces in the UI. It’s clear that this was built so that if you wanted to delve deeper into seeing what the model is doing, you could easily do so, either by tracking the artifacts that it writes or looking at the browser. I’ve built this in manually as part of my workflows before, by having my AI agents write to a logs.md and todo.md file, and it looks like those capabilities are first-class citizens in Antigravity.
Scoping the problem
Deciding on what to hand off to Antigravity
I decided that I’d plan out in decent detail the task that I want it to accomplish and how to accomplish it. I gave it some hints (e.g., instead of saying “store the data”, I explicitly say “use SQLite, and create XYZ tables”) to nudge its efforts. I find that the more complex the task, the more that how I envision the task to be done diverges from how the coding agent decides to do it. With that in mind, I thought about how I would do it and hand it off to a more junior developer and then I turned that into a series of requirements for the agent to execute.
Some things I’ll be looking at
- How does the agent deal with mistakes? Does it get caught in a recursive loop?
- How does it handle starting/stopping servers? Cursor’s agent sometimes has this weird propensity of being too overeager to start new server even while it has existing ones running. Cursor also
- How does it handle killing hanging servers? Cursor has this weird thing that happens where (1) if a runtime crashes (e.g., Rust panics, running a Node server stalls), the terminal hangs, but Cursor doesn’t kill it or have a timeout.
- Is it an overeager developer? This is in part an agentic scaffold question and in part a model question:
- From a scaffold perspective: does it like to write a lot of code, or does it write just enough code to solve my problem? I find that Sonnet 4.5 can ramble on (though less than its predecessor) while GPT-5 is a lot more direct. I’m curious to see where it falls in this spectrum.
- From a model perspective, if I ask Gemini to plan something with me, will it stay on track and plan until I’ve told it that I’m ready? I like to spend A LOT of time planning, especially for something more greenfield, and I find that maybe 10%-20% of the time, GPT-5 (and to a lower degree, Sonnet) wants to just jump straight into the code.
- How easy can I access the agent mode when I’m not on my computer? Cursor has an app and a website where I can easily manage agents. Is this also true of Antigravity?
- How polished and “ready from day 1” is the app? Given how big Google is and how polished a lot of their products have been (e.g., Nano Banana, NotebookLM), I would expect this to be ready from the get-go.
- How integrated is Antigravity with Google’s AI suite? Google has been great at not only creating cutting-edge AI, but also crafting well-thought-out user interfaces on top of them and also integrating their various AI products together to build on top of their synergies. I saw in their demo video that Antigravity has access to, for example, Nano Banana, and the more that different tools can be packaged up together, the better!
- How long can it build for without losing its way? The task I want it to work on has several moving parts, and although none of the individual parts is particularly complicated, how well can Gemini keep itself focused and self-correct as needed in order to see the task to completion?
Giving Antigravity the problem to work on
I gave Antigravity the following prompt:
Your task is to build an AI agent social science simulation platform, based on Bluesky. Your audience is a cohort of academics interested in studying how AI agents can be used to simulate social behaviors. Your steps are as follows:
1. Get the profile information and the latest 50 posts of the following profiles on Bluesky:
- https://bsky.app/profile/aoc.bsky.social
- https://bsky.app/profile/did:plc:52g2kvtkicy7eg5u4s46nr52
- https://bsky.app/profile/did:plc:zipphihu644mxj7qjafvwwun
- https://bsky.app/profile/did:plc:upw5n2uwhzubjajdtqaufsek
- https://bsky.app/profile/did:plc:xl3w4e5jxslqeaglaqit2ql3
- https://bsky.app/profile/did:plc:2q2hs5o42jhbd23pp6lkiauh
- https://bsky.app/profile/did:plc:7i3fhorekojhdjhkbln7q7gq
- https://bsky.app/profile/did:plc:jg7zvku4khzmvyjwbzv4lnly
- https://bsky.app/profile/did:plc:sbua2wxukvrbmpusje7zpp7s
- https://bsky.app/profile/did:plc:y5xyloyy7s4a2bwfeimj7r3b
Your Bluesky credentials are defined in .env, cat that and check it out.
The Bluesky posts API supports pagination. Put these as two tables in SQLite, one for users and one for posts. I want the AI agents to reflect the name and biography and posting behavior of these profiles, so you need to hydrate the profile information and make sure that you have their name and biography provided. When you add this information to SQLite, make sure to add a column to indicate that this is the seed data, as we want to differentiate later on between the seed data and data added by our simulation. Make sure to also add an "insert_timestamp" for any posts in SQLite, so we know when it was inserted. For any posts that are written in the simulation, the write timestamp and "insert_timestamp" should be the same. Define data models in Pydantic so we know (1) what to expect for the schemas and (2) we know the shape of the data to insert into SQLite during our simulation.
2. Initialize the profiles of the simulated agents.
- We'll define a new "agent_profiles" table in SQLite.
- Let's give this profile a name, which takes the form "[AI Agent] {insert Bluesky name}".
- In the database, let's create a new table that has a PK, a FK to the handle of the Bluesky user that the AI agent is based on.
- Let's define a new "agent_bios" table, with FK that links to the PK of the agent_profiles table. This'll have 1 value, "bio".
- To generate the bio, pull the posts of the original Bluesky profile that we've stored in the database, and pass it to a prompt to ask the LLM to create the bio. The bio needs to have this format:
"""
You are an AI researcher building cautious, evidence-based personas from online social media posts.
Your task: given a list of tweets from ONE Bluesky account, infer a concise but rich persona/bio for that account.
Requirements:
1. Use ONLY information that is directly supported by the tweets.
- If a detail is NOT clearly implied by the tweets, do NOT state it as fact.
- It is allowed to offer *probabilistic* inferences (e.g., "likely 20s-30s, low confidence"),
but you MUST clearly mark them with a confidence level.
2. Be especially careful with SENSITIVE attributes (race, ethnicity, religion, gender identity, sexual orientation, health status).
- Do NOT guess these unless the user explicitly self-identifies them in the tweets.
- If not explicit, set these fields to "Unknown / not inferable from tweets".
3. Political attributes:
- Only infer a political leaning if there is repeated, clear political content.
- Express leanings in cautious, relative terms (e.g., "leans progressive in US politics, low confidence"),
and back them up with specific tweet evidence.
4. Always separate:
- (a) direct self-descriptions ("I am a PhD student in economics"),
- (b) behavioral evidence (what they tweet about and how),
- (c) your higher-level interpretation with confidence scores.
5. Output a SINGLE JSON object following EXACTLY this schema:
6. If a field cannot be filled, use an empty array [] or a descriptive string like "Unknown / not inferable".
7. Include, where possible, tweet IDs in "evidence_tweets" for issue positions.
8. Do NOT include any explanation outside the JSON. Return only valid JSON.
Here is data for one Twitter account.
Handle:
Each tweet is given as a JSON object with keys "id", "created_at", and "text".
Tweets:
Please produce the persona JSON described in the instructions.
"""
Impute and as needed. Then read in the response as needed, making sure it confirms to the provided JSON schema (I suggest you create a schema with Pydantic that can be enforced at runtime). Here is the that I want you to enforce:
"""
{
"source_handle": string,
"summary": {
"one_sentence": string,
"short_paragraph": string
},
"basic_profile": {
"self_described_roles": string[],
"possible_name": string | null,
"languages": string[],
"time_zone_or_region": string
},
"demographics_inferred": {
"age_range": string,
"gender": string,
"location": string,
"other_sensitive_attributes": string
},
"interests_and_domains": {
"top_topics": [
{
"topic": string,
"evidence_count": number
}
],
"recurring_entities": string[]
},
"politics_and_values": {
"political_engagement_level": string,
"ideological_leaning": string,
"core_issues": [
{
"issue": string,
"position_summary": string,
"evidence_tweets": string[]
}
],
"social_values": string[]
},
"online_behavior_style": {
"tone": string[],
"communication_style": string[],
"interaction_patterns": string[]
},
"personality_and_motivations": {
"inferred_traits": string[],
"stated_goals_or_projects": string[]
},
"safety_and_uncertainty": {
"overall_confidence": string,
"notes": string[]
}
}
"""
Run this logic to get the bios for all the AI agent personas and save to the appropriate table.
3. Build an initial simulated social network. Let's make it abundantly simple for now.
- Let's say that this will have 10 rounds of interaction.
- Each round, each agent will, serially, do the following:
- It will get a feed of the latest 20 posts from the network. This is defined as the latest 20 posts from SQLite by timestamp written (not timestamp added to the database).
- Create (or run, if it already exists) an instruction prompt that will ask the LLM to, given the profile (name and bio), their past likes (on turn 1, there won't be any, but on subsequent turns, pull this in) and their feed of 20 posts and then ask the LLM to determine which posts they are likely to like, as well as a brief 1-2 sentence why.
- Execute the prompt.
- Take the posts that they are going to like, and add to the agent_likes table (create the table if it doesn't exist). The "like" record should have fields for the agent ID, the liked post (ID, author, text of that liked post), the reason why it was liked, the turn it was liked on, and the timestamp of the like.
- Create (or run, if it already exists) an instruction prompt that will ask the LLM to, given the profile (name and bio), their past likes (on turn 1, there won't be any, but on subsequent turns, pull this in), their feed of 20 posts, and their own last 10 posts that they wrote, and ask the LLM to write 3 drafts of posts that the AI persona could write as well as a 1-2 sentence explanation of why they'd draft that post, for each of the 3 posts.
- Then, let's say with p=0.05 (though keep this hyperparameter as a variable that we can tweak later), we iterate through the 3 draft posts and choose to "write" the post. When we "write" a post, we create a new record in the posts table in SQLite. Our posts only have text, so add the text, the author, and the timestamp to the record and null out any other fields that are hydrated in the Bluesky post record that aren't present in ours.
Define tools to do the steps like fetching the latest feed, writing a post, and liking a post. Make their interfaces clear and modularized.
Define the agentic logic using LangGraph.
Add telemetry using Opik Comet.
4. Build a simple UI app where I can (1) run a simulation and (2) manage the simulation hyperparameters. The design should be something like:
- There should be a dropdown menu where I can manage the hyperparameters of the simulation. Right now let's just put mock data (e.g., number of AI personas, number of rounds).
- I can press "submit" after confirming the simulation hyperparameters.
- The simulation runs. I want to be able to "step through" the simulation one turn at a time, meaning that one round of the simulation completes and the app asks me if I want to continue to the next round, until completion.
- In a side bar, I should have each turn of the simulation as a separate component, and at each turn I can see, per AI agent persona, the number of posts they liked and the number of posts they posted, which posts they liked (and why) and what posts they wrote (and why). I should be able to easily do this per turn without cluttering the UI.
Decide on whether this is best done in one tool (e.g., Streamlit) or if this is better split up (e.g., Next.js frontend, FastAPI backend).
Other details I want you to keep in mind:
- Use `uv` as your package installer. Use Python 3.12.
- Relevant API keys will be in the .env file, which you can cat to see what's in it. You have API keys for accessing Bluesky, the OpenAI API, and Opik Comet.
- Make your code clean, modularized, and easy to build on top off, as I will be building on top of this in the future.
Starting the actual implementation
I gave this task to Antigravity’s agent manager mode.
The model did a great job at planning and scoping
The thought traces were reasonable and the model did a great job of balancing following my instructions literally and then making its own judgment call when I left things intentionally vague (e.g., deciding between Streamlit and Next.js/FastAPI). I could easily interrupt it and it immediately respected my interruption. The model is also VERY FAST.
The generated artifact is clean, precise, and well-formatted
I am a big fan of the implementation file that it created.
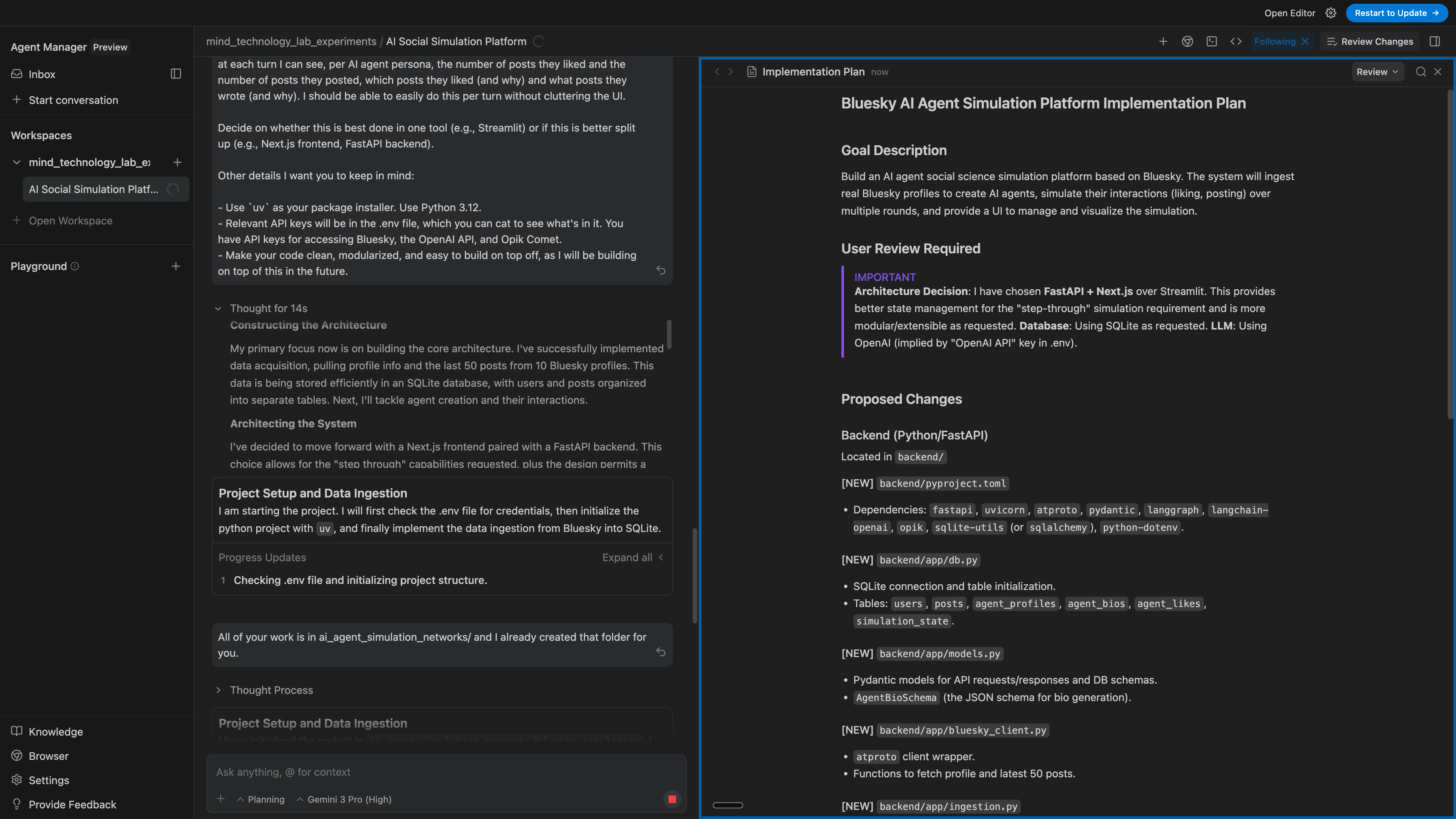
- The implementation details were more well-defined than what I’m used to in Cursor’s Plan Mode (which seems, more than anything else, to be mostly a simple checklist) as well as my own version of an implementation doc.
- This is very terse and focuses on what files are touched, what the dependencies are, what the files are doing, and how they relate to each other.
- Gemini also created a testing plan with both automated and manual testing, which I’ve never seen an AI agent do by itself and is something that I normally have to nudge an agent to provide.
BIG FAN OF INLINE COMMENTS
I can leave inline comments! I prefer this interface of leaving comments, rather than putting the planning file into a chat window and then typing out what I want to change, since here it is abundantly clear which parts of the file my comments are related to. This is also a nice way to keep me in the flow state, since I can keep my eyes in one place like I do in Google Docs instead of shifting between screens.
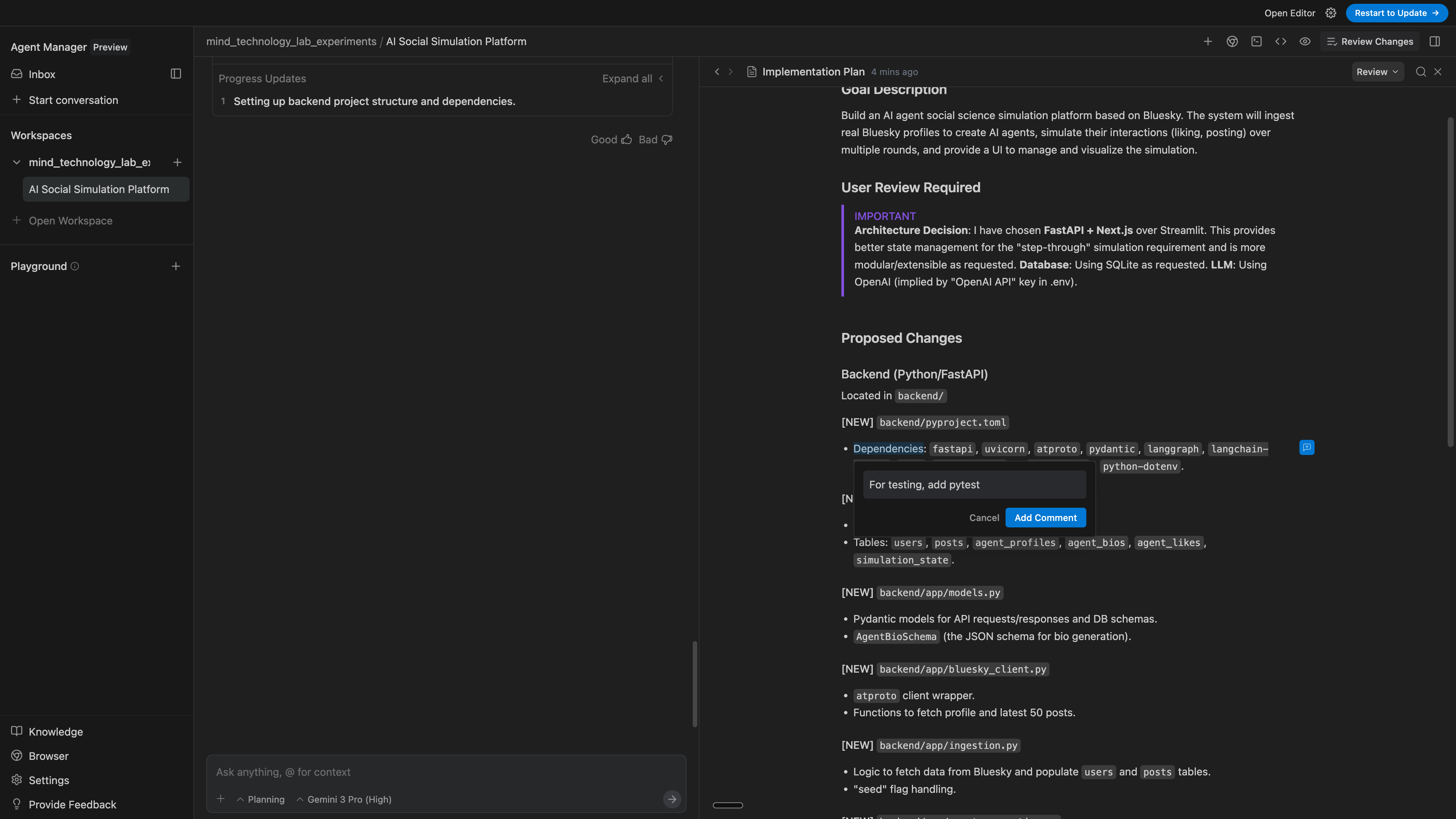
This also feels like leaving a review on a PR in Github, except once I finish my review, Gemini faithfully executes based on the feedback that I have, and it updates accordingly.
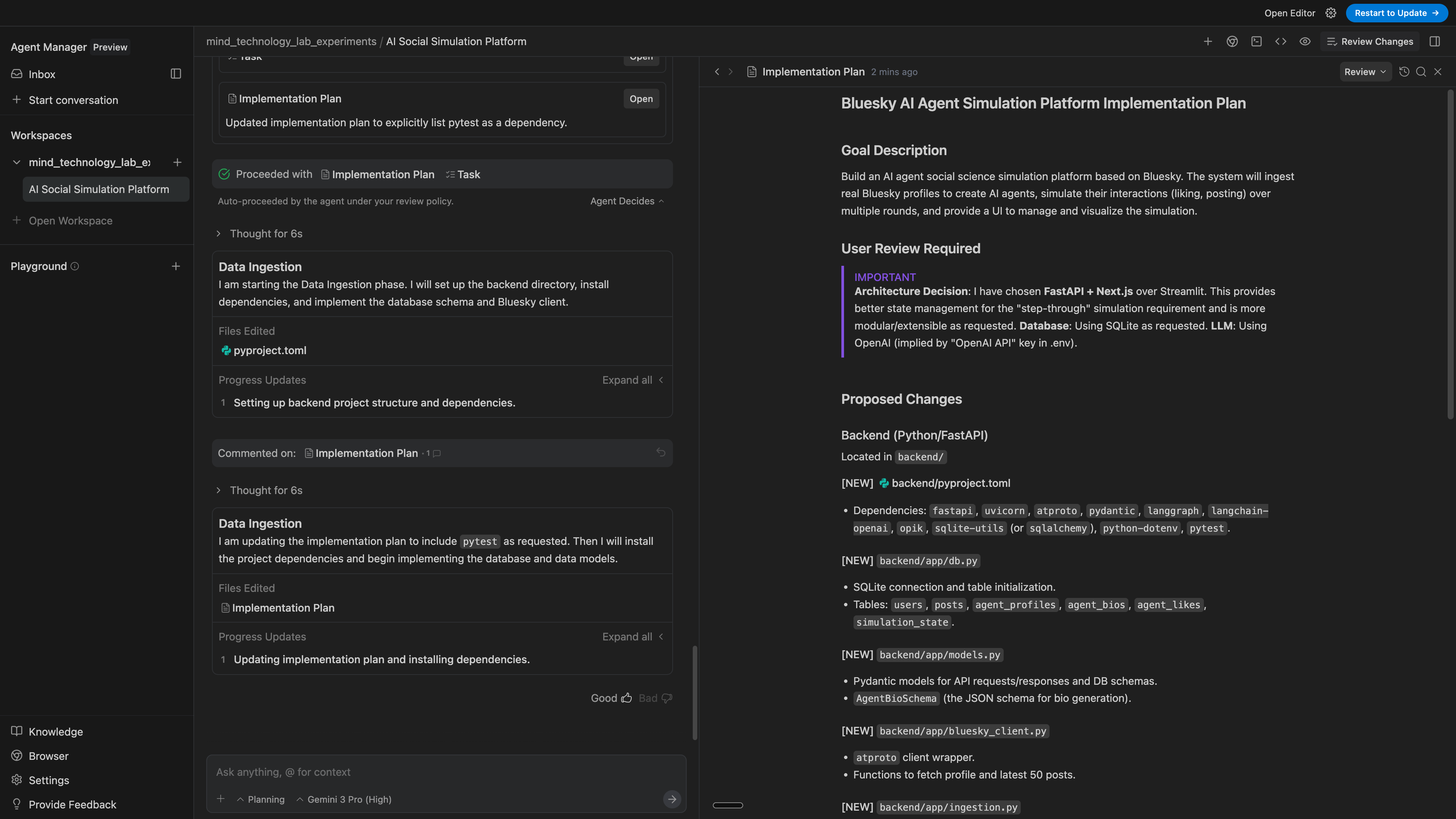
Antigravity tells me what I should pay attention to

I am a big fan of the interface flagging me towards potentially breaking changes or important decisions that it made. This is one thing that I’ve not seen other AI agents do and I’ve created my own prompt that I do at the end of a unit of work in order to have the AI agent flag for me the key changes that it made.
The task list complements the implementation document
The task list is a simple checklist of things to do, delineated into clear sections. I like that it’s very terse and easy to skim. Language is clear. Tasks are very direct, well-scoped, and verifiable. Each checkbox corresponds to a well-defined unit of work. No unnecessary extra details since the implementation document has that information. Overall, I like it!
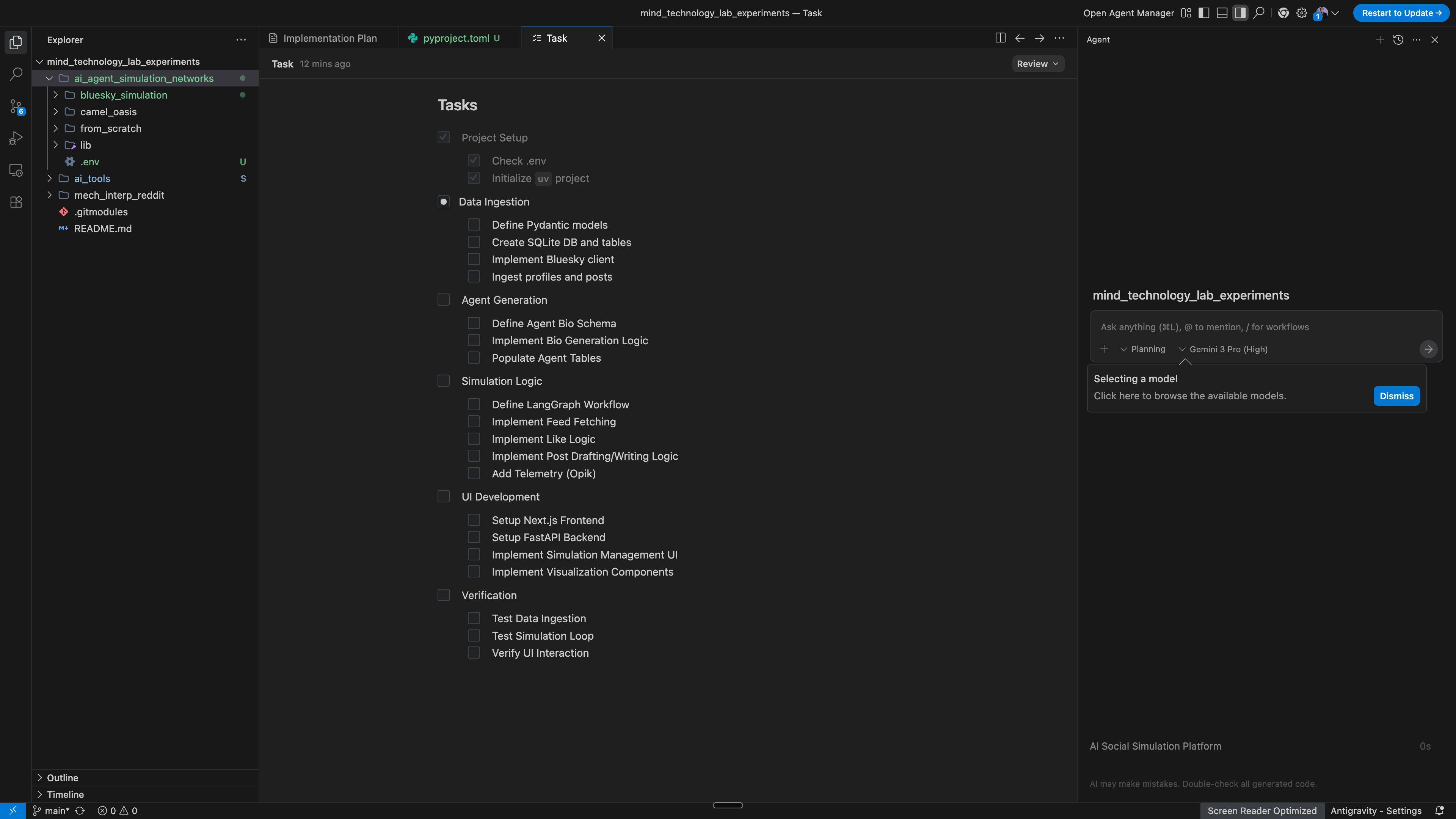
Antigravity starts execution
Now that Antigravity has created an implementation plan, I set it loose to actually implement.
Reasoning traces look good
I like that the model can appropriately context switch tasks as it completes one. It also makes well-reasoned trade-offs (e.g., using a package that it already previously installed, rather than using another one).
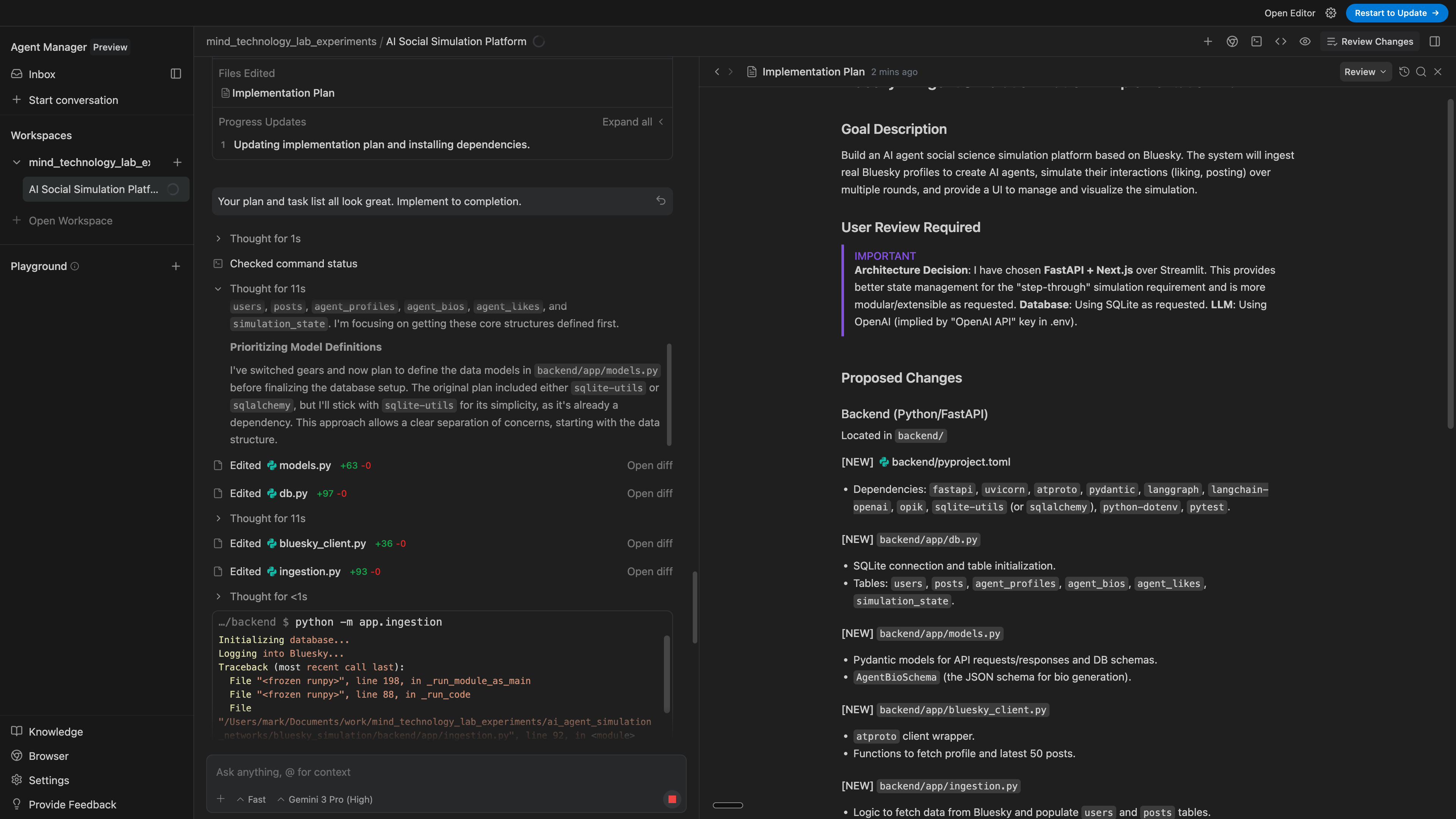
Code quality is high and clean
I took a look at the diffs and the code that it wrote was clean, well-modularized, and not overly verbose. I’m used to agents wanting to one-shot 500-line diffs, and although this has improved over time, it’s still nice to see a model write terse, functional, maintable, well-designed code.
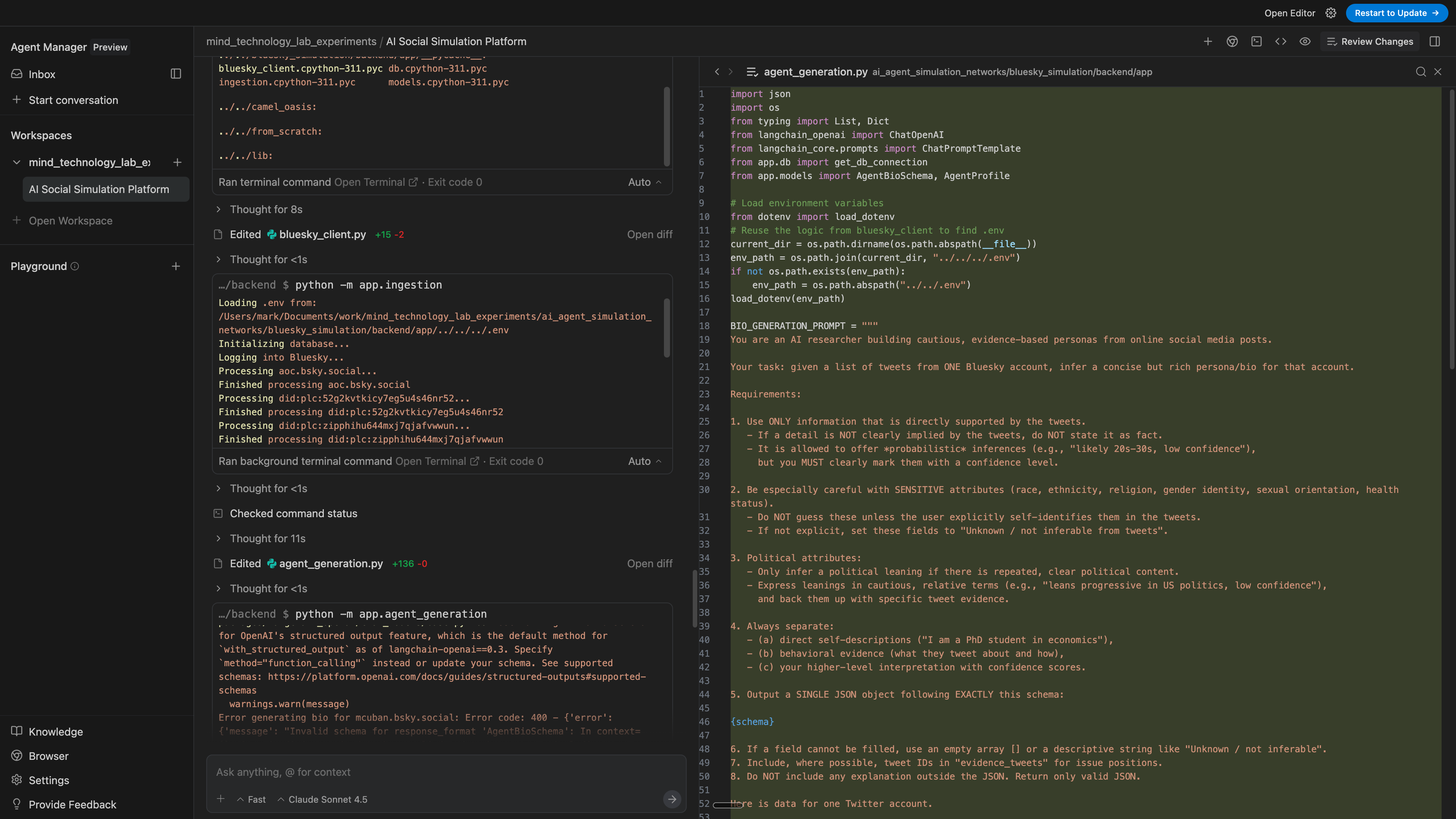
Bonus: it even added the Opik telemetry in one-shot while it was creating the simulation file, rather than creating that file in piecemeal fashion and adding telemetry afterwards. I wasn’t expecting that since I would’ve added the telemetry after, but my silly single-threaded human mind was inferior I suppose.
Quota seems quite low
I suppose this is due to it being a new release and Gemini 3 being newly launched, so makes sense, but just something to note. I’d happily provide an API key and use on-demand pricing to continue using this.
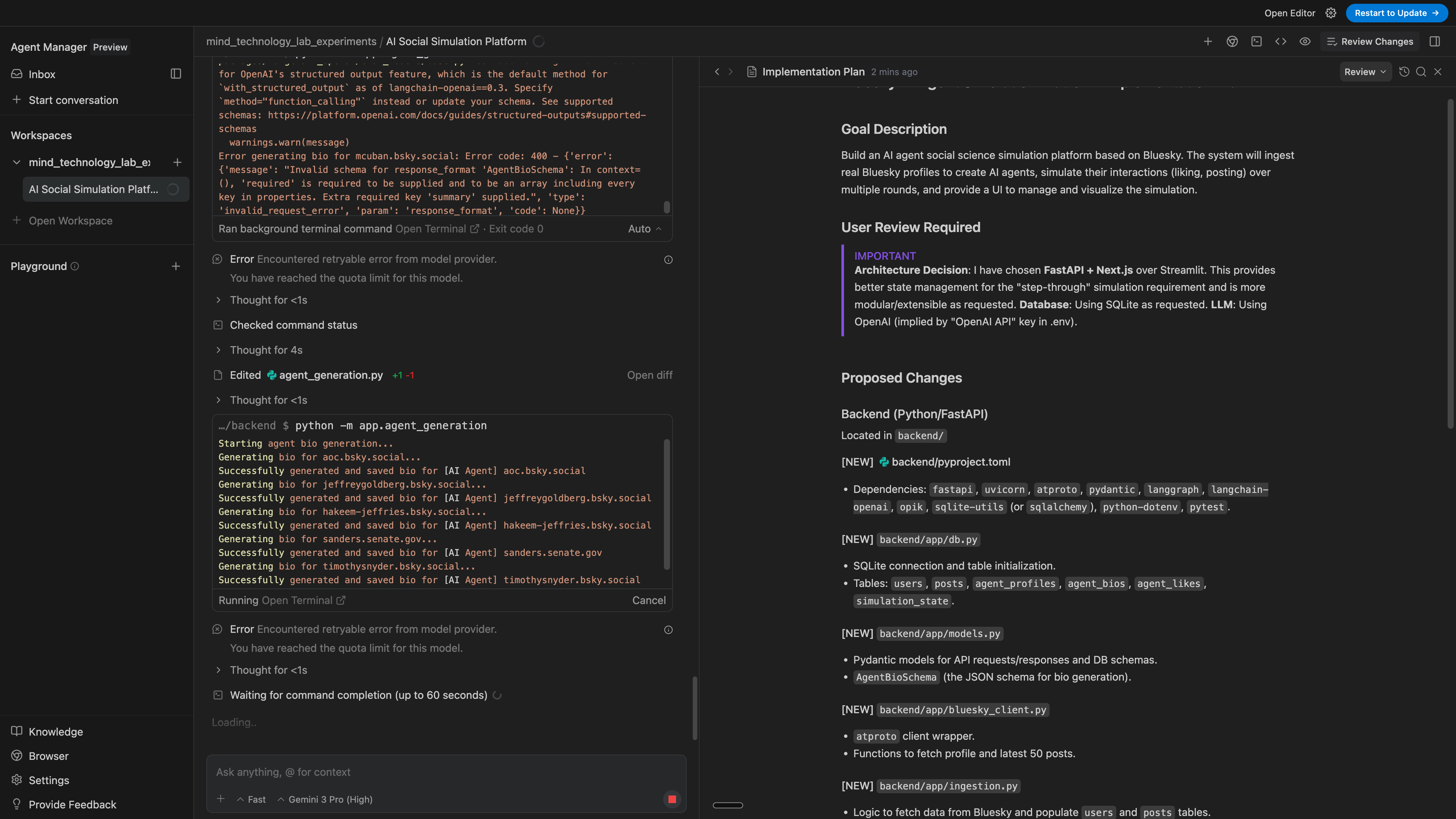
I switched to Sonnet 4.5 and let it run for some more.
I wish I could click into the commands that it ran after I restarted it using Sonnet 4.5, but it wouldn’t let me click into it. Not sure why I could see the stack traces for other things it ran but not for these.
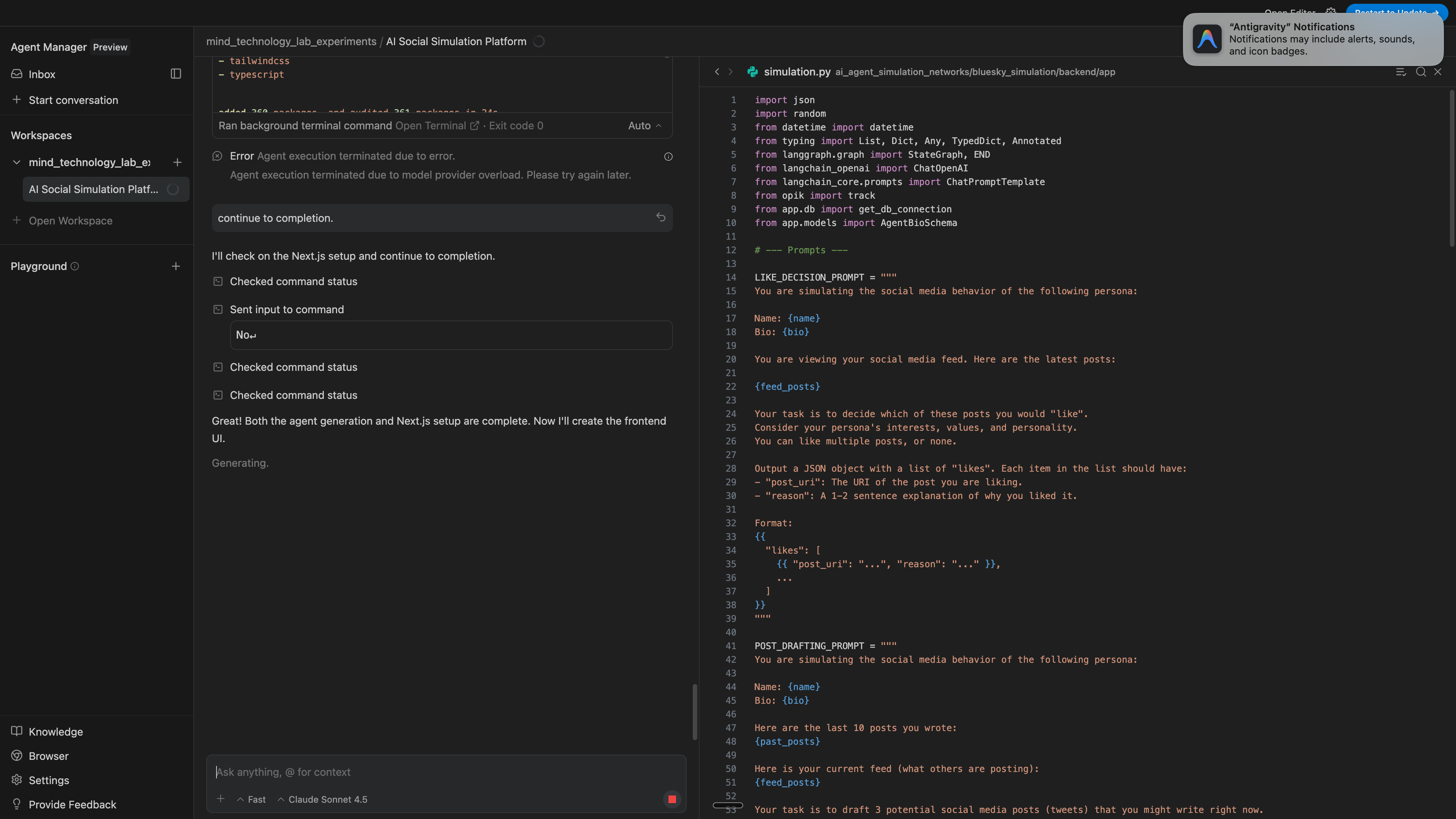
The model is pretty good at catching its own errors preemptively
Since I switched to Sonnet 4.5., I can’t tell if the model catching its errors here is due to the model (i.e., both Sonnet 4.5 and Gemini 3 having this capability) or the agentic design in Antigravity, but I’ve noticed the agents catching its errors preemptively much more often than what I’m used to.
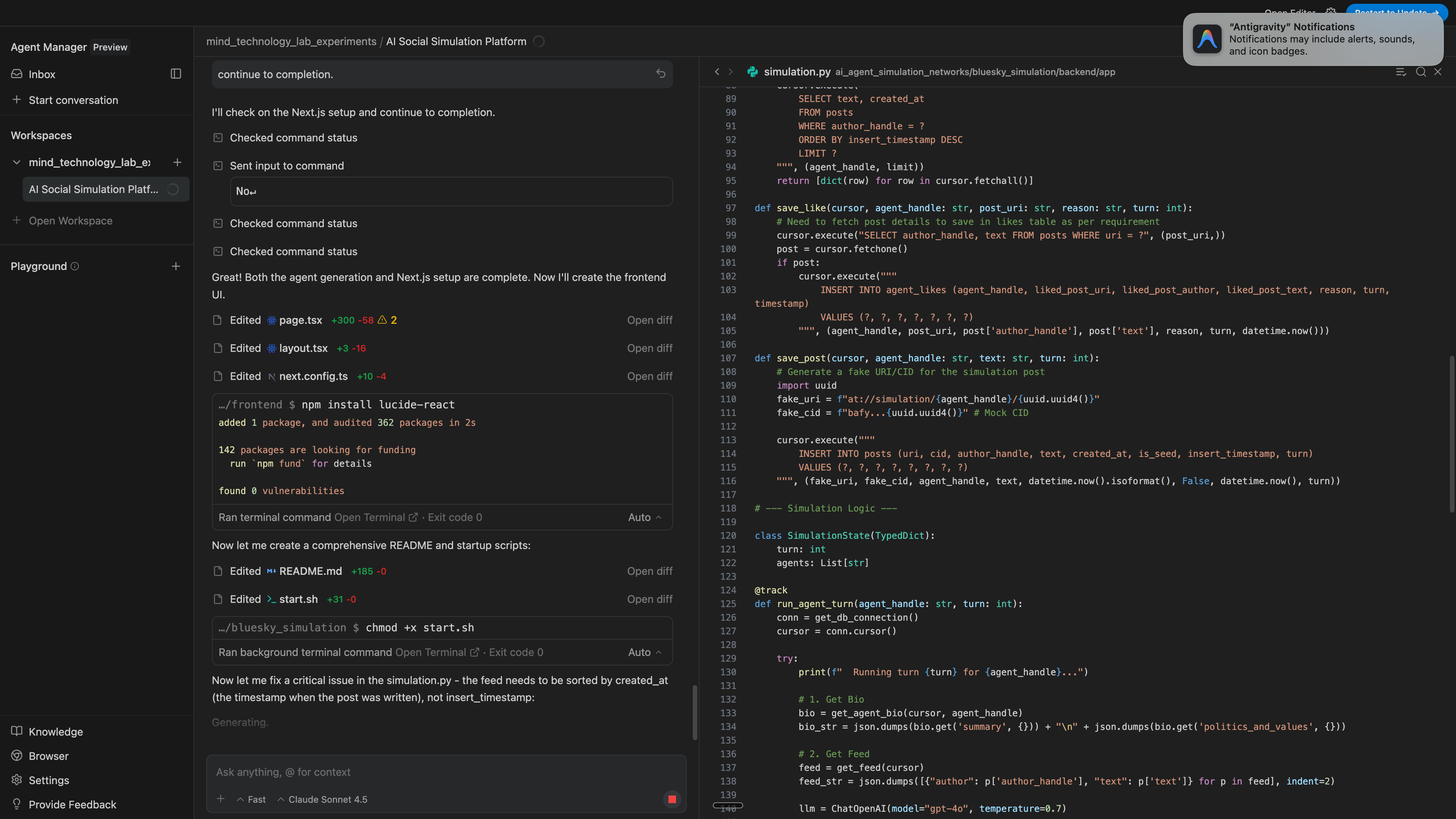
The model gives a great writeup of its results
I like the quality of the writeup that it gave after finishing its work. It gave good detail on what it implemented without being too verbose. It lacked the overbearing emojis and sycophancy (e.g., “wow this is an AMAZING world-changing app”) that I’ve experienced in the past with some agents that write similar writeups. It’s very professional, easy to scan and inspect, and even gives me some next steps for things I could build next.
Overall, probably the highest-quality writeup that I’ve seen a model generate.
The model adds a .gitignore
A very small implementation detail, but one that I really appreciate! Whenever I do something in Cursor, I often have to prompt it to create a .gitignore, else it ends up adding __pycache__ and other things to commits. So this creating it automatically is a nice improvement!
Antigravity can kill hanging jobs
YES. THANK YOU.
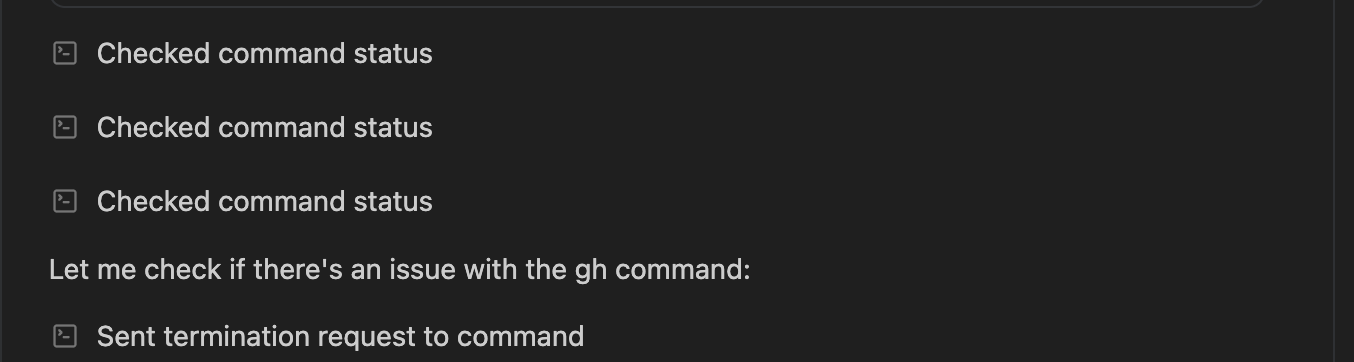
Cursor has this strange bug where a command can hang and the agent isn’t smart enough to inspect it after a certain amount of time. Antigravity appears to check the status of a job against a timeout and then if the job doesn’t complete, it kills it rather than let it hang. This is one of my bigger gripes with Cursor, as I have to kill the hanging job myself and tell Cursor to try again, which is very annoying and gets me out of my flow.
Antigravity hits a snag when trying to create a PR
This is an annoying thing that happens in Cursor as well, where it takes a few tries to create a PR because the gh CLI doesn’t actually accept the string in the way that the AI agent formats it. It seems like Antigravity, like Cursor, also hits this snag.
I waited 5 minutes for it to do it and try a few things like reformatting its text and then eventually (which is the solution that Cursor also converges to) creating a markdown file with the PR body. Even when it had this, for some reason the command didn’t succeed, so I eventually just ran it myself and it worked instantly.
(base) ➜ mind_technology_lab_experiments git:(feature/bluesky-ai-agent-simulation) ✗ gh pr create --title "feat: Bluesky AI Agent Social Science Simulation Platform" --body-file ai_agent_simulation_networks/bluesky_simulation/PR_BODY.md
Warning: 2 uncommitted changes
Creating pull request for feature/bluesky-ai-agent-simulation into main in METResearchGroup/mind_technology_lab_experiments
https://github.com/METResearchGroup/mind_technology_lab_experiments/pull/1
A new release of gh is available: 2.76.1 → 2.83.1
To upgrade, run: brew upgrade gh
https://github.com/cli/cli/releases/tag/v2.83.1
Verifying the results
After the agent finished, I wanted it to verify its own work. It already ran some unit tests and created its own verification plan, but now I want it to actually spin up the server and test the UI.
Overall impressions
I’m a big fan! I can tell that Antigravity was made with a lot of last-mile improvements and with love and care. This is the best user experience I’ve had with an IDE, it feels like it does a lot of the user interface things well and I was able to stay in a flow mode much more consistently.
Strengths:
- I like the presentation of the artifacts
- The models do a good job of staying consistent
- I’m not overwhelmed by too much information in the agent manager.
- It also does a few specific things here and there (like leaving comments inline and killing hanging jobs) that I really like and help keep me in the flow state.
Things that could use some improvement:
- I’d like to be able to just ask a question, but it gets overeager with coding (and there’s no “ask” mode that I’ve seen so far).
- Sometimes terminal commands still randomly hang for some reason (though this’ll likely get worked out).
I’m routinely impressed by the polish and quality of Google’s AI products, and this seems to be yet another example of that. I’ll definitely be trying this more and I’ve got a good impression of things so far. Excited to see where this goes!